
最近看了很多有关差分隐私的概念文章,一直都没有搞懂具体怎么实现的,这篇文章让我有种豁然开朗的感觉,故而记录一下,原创是csdn的一位博主,我只做自己的笔记转载,原文链接:隐私计算--18--差分隐私技术
一、差分隐私的概念
差分隐私是为了解决差分攻击而引入的解决方案,它可以有效防止研究人员从查询接口中找出自然人的个人隐私数据。其原理是在原始的查询结果(数值或离散型数值)中添加干扰数据(即噪声)后,再返回给第三方研究机构;加入干扰后,可以在不影响统计分析的前提下,无法定位到自然人,从而防止个人隐私数据泄露。
差分隐私主要适用于统计聚合数据(连续的数值,或离散的数值),如交互式统计查询接口、API接口、用户侧数据统计等。
二、差分隐私原理
为了防止攻击者利用减法思维获取到个人隐私,差分隐私提出了一个重要的思路:在一次统计查询的数据集中增加或减少一条记录,可获得几乎相同的输出。 也就是说任何一条记录,它在不在数据集中,对结果的影响可忽略不计,从而无法从结果中还原出任何一条原始的记录。
假设原始数据集为D(可以理解为一张表),在其基础上增加或减少一条记录构成D',这时D和D'为临近数据集;假设某个差分隐私算法为A(),对数据集D运算并添加噪声的结果为A(D) = V;对数据集D'运算并添加噪声的结果为A(D') = V';V和V'就是统计运算的结果,差分隐私要求对临近数据集的运算结果基本一致,即V = V'。 选用不同的输入,输出也会不同,我们用P()表示A(D) = V的概率,则对于所有的输出V,要求:
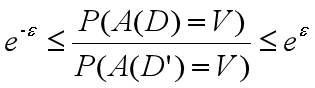
在数学上,当ε比较小时,大致是这样:
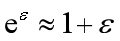
于是,当ε比较小时,公式也可以写为:
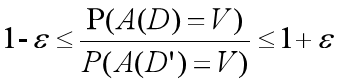
这个公式可以帮忙理解差
ε 被称为隐私保护预算,用于控制隐私保护算法A()在邻近数据集上获得相同输出的概率比值。 ε 越小,隐私泄露的风险就越小,但是引入的噪声就越大,输出的数据集的研究价值也越小。如果 ε = 0,则表示该差分隐私算法在所有邻近数据集上获得了完全相同的输出,即不可能泄露任何用户的隐私,但这样对研究机构来说就没有研究价值了
差分隐私从数学上证明了,即使攻击者已掌握除某一条指定记录之外的所有记录信息(即最大背景知识假设),它也无法确定这条记录所包含的隐私数据。
三、差分隐私噪声添加机制
通常使用如下机制来实现差分隐私保护:
● 拉普拉斯(Laplace)机制,在查询结果里加入符合拉普拉斯分布的噪声(也可以在输入或中间值加噪声),用于保护数值型敏感结果;
● 指数(Exponential)机制,用于保护离散型敏感结果(如疾病种类)。
四、数值型差分隐私
针对数值型查询结果,差分隐私从数学上证明,如下在结果上添加噪声的公式,满足ε -差分隐私要求:
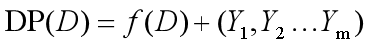
对于Y来讲:
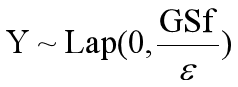
其中:
● DP(D)表示基于数据集D添加了噪声的结果输出;
● f(D)表示未添加噪声的基于数据集D的原始查询的结果,结果可以是多维的,如二维(sum_a, sum_b);
● Yn表示每个维度的噪声,服从参数 μ = 0,b = GSf/ε的拉普拉斯分布;
● GSf = max||f(D) - f(D')||表示f(x)的全局敏感度,为函数f(D)作用在所有临近数据集的曼哈顿距离的最大值;由于临近数据集有很多对,需要取最大值才能避免隐私泄露。
所谓曼哈顿距离,就是所有维度上的距离之和,而不是直线距离; 如果固定数据集D(是原始数据集中的一个子集),计算与其所有临近数据集的曼哈顿距离的最大值,则为局部敏感度。所有局部敏感度的最大值,即为全局敏感度。
Lap( μ ,b)表示拉普拉斯分布函数,其中为位置常数,默认取0,b为尺度参数,取值GSf/ε,
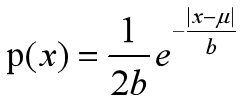 而对于符合拉普拉斯分布的噪声的公式如下:
而对于符合拉普拉斯分布的噪声的公式如下:
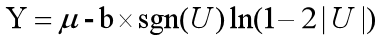
其中:
● sgn()表示符号函数,正数为1,负数为-1
● U是服从(-0.5, 0.5)区间均匀分布的随机数 这样计算出来的结果符合拉普拉斯分布。
将GSf/ ε 作为尺度参数b,即可得到在原始查询结果上添加噪声的输出DP(x)
在实践中,数值型差分隐私的全局敏感度对于单个返回值的场景表现较好,但不太适合复杂的具有多个返回值的复杂查询场景,特别是多个返回值不在同一量
五、离散型差分隐私
我们假设这样一个场景: 在足球协会的一次在线选举投票中,得票最多的候选人将出任协会主席,共收到100张投票,三位候选人实际得票如下:张三50票、李四35票、王五15票。该场景下隐私保护的目标是:任何人都不能知道其中具体的任何一张票投给了谁。
为了防止投票人隐私泄露,不再输出每个候选人的得票数,而是输出每位候选人添加干扰后的胜出概率。 投票记录中记录的,是三位候选人的名字,是离散型的结果,而不是数值。
用代码来验证一下:
import numpy as np
def calc_proportion(epsilon, value, delta):
return np.exp(epsilon * value / (2 * delta))
ghgfhjfwenzhanglaixzizhenggegedboke@@@@ if __name__ =='__main__':
candidate = ['zhangsan', 'lisi', 'wangwu']
vote_count = [50, 35, 15]
epsilon = 0.1 # ,自定义大小
delta = 1 # 敏感度
proportion = [] # 所占份额
result_probability = [] # 最终胜出的概率
total_proportion = 0.0
for i in range(len(candidate)):
proportion.append(calc_proportion(epsilon, vote_count[i], delta))
total_proportion += proportion[i]
for i in range(len(candidate)):
result_probability.append(proportion[i]/total_proportion)
print(result_probability)运行结果为:
[0.6074815620620585, 0.28695397132498135, 0.10556446661296022]张三以约60.75%概率胜出。
下面我们看看这个概率是否符合差分隐私的定义。将张三的得票减去一票(50改为49),概率结果为:
[0.5954972684652321, 0.2957151919677618, 0.108787539567006]张三的胜出概率变为59.55%。60.75%/59.55%约等于1.02,exp(-0.1)约等于0.90,exp(0.1)约等于1.11,从而:
exp(-0.1) < (60.75% / 59.55%) < exp(0.1)
可见,符合ε -差分隐私(ε = 0.1)的定义。
如果 ε = 0,输出如下所示:
[0.3333333333333333, 0.3333333333333333, 0.3333333333333333]输出已经没有任何差异,不会泄露任何隐私,但数据没法用了。
如果 ε = 0.5,输出如下所示:
[0.9768713905676077, 0.022973813097375215, 0.0001547963350170097]如果 ε = 1,输出如下所示:
[0.9994471962808382, 0.0005527786230510056, 2.509611066071874e-08]可见当增大时,得票最多的选项(“张三”),其胜出概率被极度放大了。因此,的选择,需要在保障数据可用的前提下进行权衡。