
差分攻击--去标识化代码实现
去识别化
去识别化是从数据集中删除标识信息的过程。术语去识别化有时与术语匿名化(de-identification)和假名化(pseudonymization)同义
识别信息没有正式定义,通常被理解为在生活中唯一识别我们的信息,例如姓名,性别,电话号码等。所有信息都是可识别的,而去识别化就和其定义所说的那样,将个人敏感信息删除,以便他人在获取信息的过程中不会暴露个人敏感信息。
数据处理
这里使用美国人口普查个人信息的数据集CSV文件,CSV 是一种通用的、相对简单的文件格式,被用户、商业和科
数据传送门:adult_with_pii_2.csv
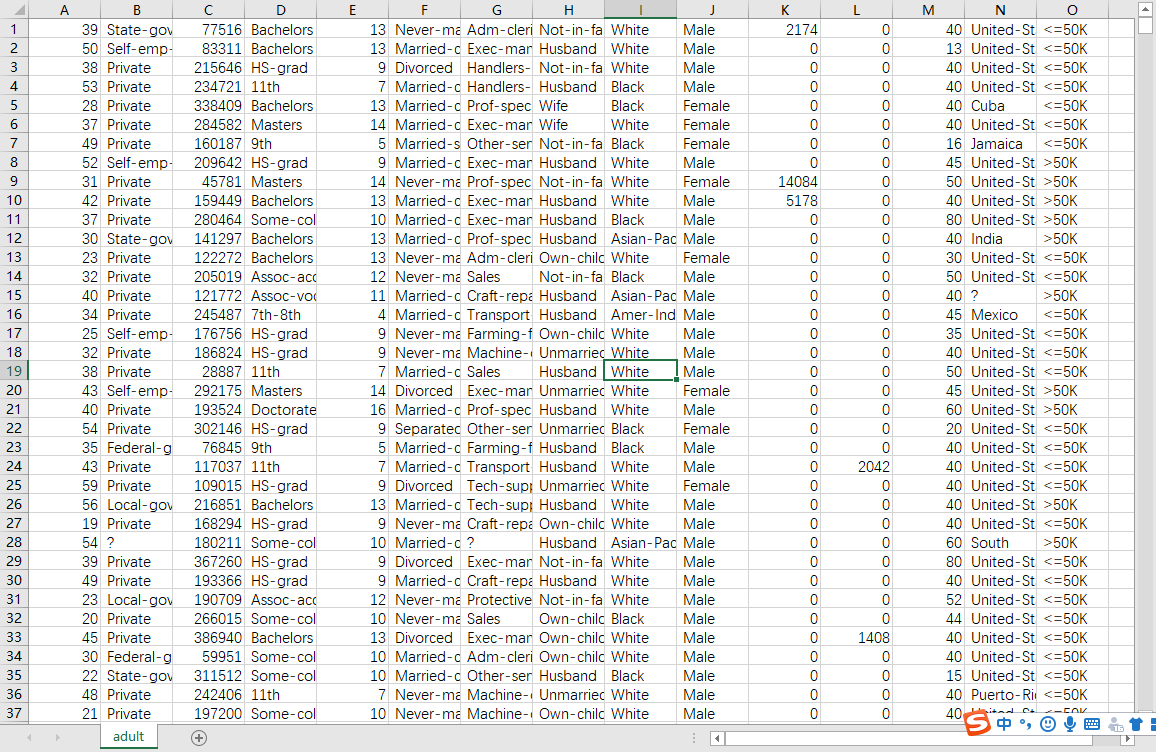
其中的属性有以下这些:
Name,DOB,SSN,Zip,Age,Workclass,fnlwgt,Education,Education-Num,Marital Status,Occupation,Relationship,Race,Sex,Capital Gain,Capital Loss,Hours per week,Country,Target接下来使用python的pandas模块对数据进行读取,这里只读取5行看看
去识别化操作
adult_data = adult.copy().drop(columns=['Name', 'SSN'])
adult_data.head(1)将之前所得的数据复制一份,去除掉‘Name’,‘SSN’就可以得到去除姓名等敏感信息后的处理结果了,输出第一行的结果如下:

再来一个,这次我们保留一些需要的信息
adult_pii = adult[['Name', 'SSN', 'DOB', 'Zip']]
adult_pii.head(1)
假设这是两个处理后的数据集,然后发布出去
链接攻击
想象一下一个场景,如何从去识别化的数据中确定一个人的收入,这个人的名字已被删除,但碰巧知道一些关于这个人的辅助信息。比如有个人叫Karrie Trusslove,我们知道Karrie的出生日期和邮政编码,也就是说我们可以结合adult_pii数据集,执行简单的链接攻击,尝试攻击的数据集和所知道的辅助数据之间的重叠列。
两个数据集都有出生日期和邮政编码。我们在数据集中查找与Karrie的出生日期和邮政编码匹配的行。如果只有一个这样的行,我们已经在我们正在攻击的数据集中找到了Karrie的行。在数据库中,这称为两个表的联接,我们可以在 Pandas 中使用 .merge
karries_row = adult_pii[adult_pii['Name'] == 'Karrie Trusslove']
pd.merge(karries_row, adult_data, left_on=['DOB', 'Zip'], right_on=['DOB', 'Zip'])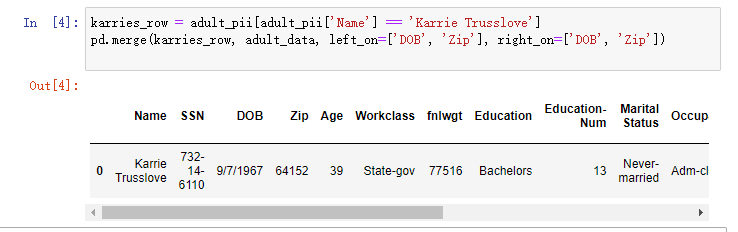
匹配成功,完成攻击。当我们使用辅助数据在去识别化的数据集中重新识别一个人,我们能够推断出Karrie的收入不到5万美元。我们还可以更简单一点,只使用邮政编码这一个属性就可以得到Karrie的信息
pd.merge(karries_row, adult_data, left_on=['Zip'], right_on=['Zip'])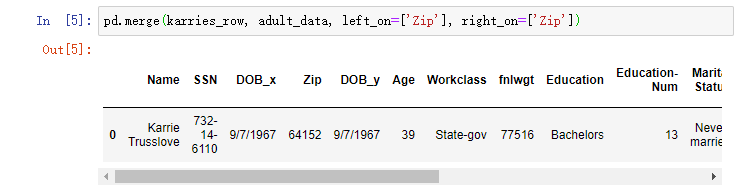
那如果通过生日进行查找呢?
pd.merge(karries_row, adult_data, left_on=['DOB'], right_on=['DOB'])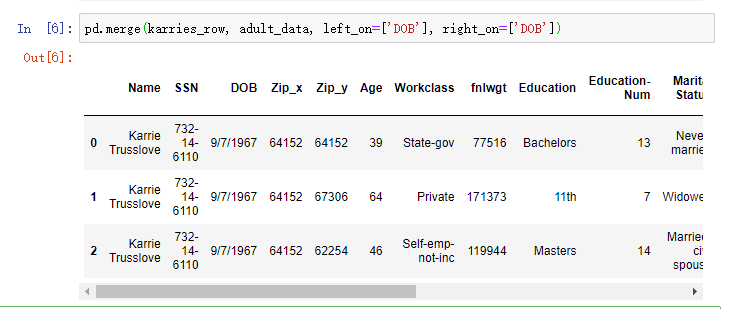
哪一行是真正的Karrie?我们不知道,但仍然可以从中获取很多东西,比如:
1、Karrie的收入有2/3的可能性低于5万美元。
2、我们可以查看行之间的差异,以确定哪些额外的辅助信息可以帮助我们区分它们(例如性别,职业,婚姻状况)
Karrie特别吗?
再次识别数据集中的其他人有多难?
Karrie是特别容易还是特别难以再次识别?
衡量此类攻击有效性的一个好方法是查看某些数据的"选择性"程度 ,它们在缩小可能属于目标个体的潜在属性方面有多少。例如,同一个出生日期是否经常出现多次?
我们想了解有多少出生日期可能在执行攻击时有用,我们可以通过查看数据集中"唯一"出生日期的常见程度来做到这一点。怎么做到查看这一点?使用以下代码:
adult_pii['DOB'].value_counts() .hist()
plt.xlabel('Number of Dates of Birth')
plt.ylabghgfhjfwenzhanglaixzizhenggegedboke@@@@ el('Number of Occurrences');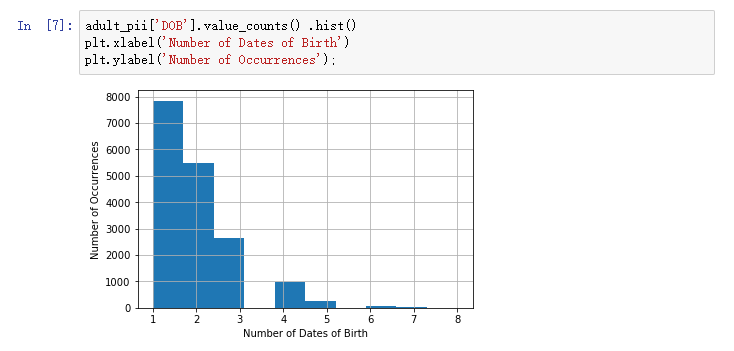
上面的直方图显示,绝大多数出省日期在数据集中出现1次、2次或3次,出生日期的出现次数最多不超过8次。这意味着出生日期是相当有选择性的,它可以有效地缩小个人的可能记录,如果使用邮政编码呢?
adult_pii['Zip'].value_counts().hist()
plt.xlabel('Number of ZIP Codes')
plt.ylabel('Number of Occurrences');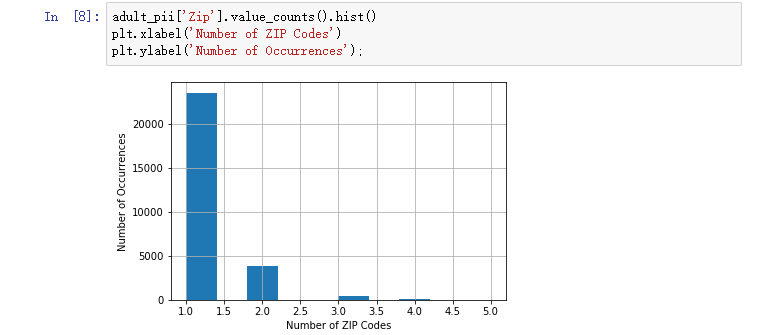
邮政编码出现一次的频率更高,效果更好。
我们可以重新识别多少人?
我们知道这些趋于唯一性的标识之后,就有一个问题,我们可以重新识别多少人?
使用辅助信息来找出答案!
首先,让我们看看出生日期会发生什么。
我们想知道数据集中的每个数据记录返回了多少个可能的标识。怎么做?上代码!
attack = pd.merge(adult_pii, adult_data, left_on=['DOB'], right_on=['DOB'])
attack['Name'].value_counts().hist();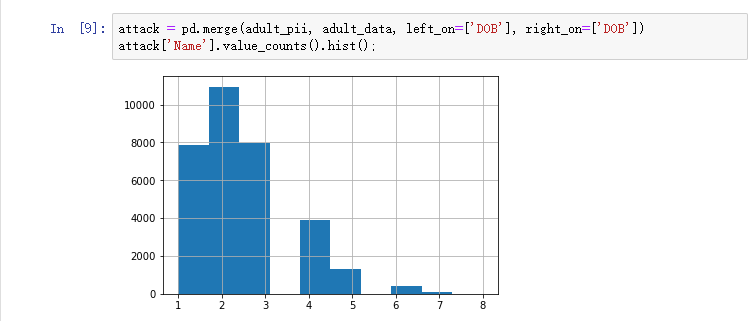
结果表明,我们可以唯一地识别近7000条数据记录(总记录的数据量为32000条),另外10000条数据被缩小到两个可能的身份
因此,仅使用出生日期就不可能重新识别大多数个体。如果我们收集更多信息,以进一步缩小范围,该怎么办?如果我们同时使用出生日期和ZIP,我们可以做得更好。
事实上,我们能够唯一地重新识别整个数据集。
attack = pd.merge(adult_pii, adult_data, left_on=['DOB', 'Zip'], right_on=['DOB', 'Zip'])
atghgfhjfwenzhanglaixzizhenggegedboke@@@@ tack['Name'].value_counts().hist();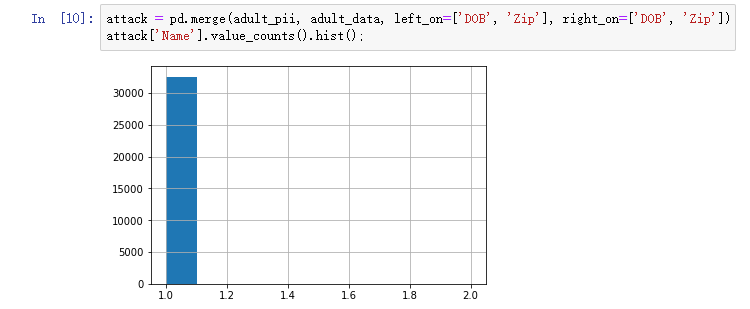
当我们使用这两条信息时,我们基本上可以重新识别每个人。这是一个令人惊讶的结果,因为我们通常假设许多人共享相同的生日,并且许多人居住在相同的邮政编码中。事实证明,这些因素的结合是极具选择性的。根据Latanya Sweeney的工作[1],87%的美国人可以通过出生日期,性别和邮政编码的组合来唯一地重新识别。
让我们检查一下,我们实际上已经重新识别了每个人,通过打印出每个身份的可能数据记录的数量,这里就看看前5条就可以了:
attack['Name'].value_counts().head()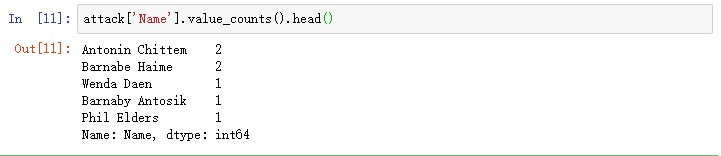
前两行有问题!在数据集中,只有两个人共享邮政编码和出生日期的组合。
聚合(Aggregation)
防止私人信息发布的另一种方法是仅发布聚合数据
adughgfhjfwenzhanglaixzizhenggegedboke@@@@ lt['Age'].mean()
小团体问题
在许多情况下,汇总统计数据被分解为更小的组。
例如,我们可能想知道具有特定教育水平的人的平均年龄
adult[['Education-Num', 'Age']].groupby('Education-Num').mean().head(3)
聚合应该对保护隐私有所贡献,因为很难识别特定个人对聚合统计信息的贡献。
但是,如果我们在一个只有一个人的群体中聚合呢?
在这种情况下,汇总统计数据准确地揭示了一个人的年龄,并且根本不提供隐私保护!
在我们的数据集中,大多数人都有一个唯一的邮政编码 - 所以如果我们按邮政编码计算平均年龄,那么大多数"平均值"实际上揭示了一个人的确切年龄。
adult[['Zip', 'Age']].groupby('Zip').mean().head()
例如,美国人口普查局在区块级别发布汇总统计数据。
一些
上述情况,即小团体阻止聚集隐藏有关个人的信息,事实证明这是相当普遍的。
一个群体"足够大",总统计数据可以提供帮助吗?很难说,因为这取决于数据和攻击 ,因此很难建立对汇总统计数据真正保护隐私的信心。
但是,即使是非常大的组也无法使聚合完全可靠地抵御攻击,比如差分攻击。
差分攻击
当对相同数据发布多个聚合统计信息时,聚合对隐私保护的程度会变得低。
例如,考虑对数据集中的大型组执行以下两个求和查询:
1、针对整个数据集
adult['Age'].sum()2、针对除一个记录之外的所有记录
adult[adult['Name'] != 'Karrie Trusslove']['Age'].sum()
聪明的小伙伴肯定知道要做什么,做差得到Karrie的年龄!
adult['Age'].sum() - adult[adult['Name'] != 'Karrie Trusslove']['Age'].sum()
即使聚合统计信息位于非常大的组上,这种攻击也可以继续进行。
那么问题来了~
1、发布有用的数据使得确保隐私变得非常困难。
2、我们无法区分恶意和非恶意查询。
总结
链接攻击涉及将辅助数据与去识别化数据相结合,以重新识别个人身份。在最简单的情况下,可以通过包含这些数据集的两个表的联接来执行链接攻击。
简单的链接攻击出奇地有效:只需一个数据点就足以将内容缩小到几条记录,缩小的记录集有助于建议可能有用的其他辅助数据。两个数据点通常足以重新识别特定数据集中人口的很大一部分,三个数据点(性别,邮政编码,出生日期)唯一地识别了美国87%的人。