
本地化差分隐私
本文是笔者在阅读《本地化差分隐私研究综述》时所写下的笔记,留下了一些自认为比较重要的知识点,权当是学习笔记不做其他用途。
论文DOI:10.13328/j.cnki.jos.005364,URL:[知网原文]
中心化差分隐私对于敏感信息的保护始终基于一 个前提假设:可信的第三方数据收集者,即保证第三方数据收集者不会窃取或泄露用户的敏感信息.
本地化差分隐私技术继承自中心化差分隐私技术,同时扩展出了新的特性,使该技术具备两大特点:
(1) 充分考虑任意攻击者的背景知识,并对隐私保护程度进行量化;
(2) 本地化扰动数据,抵御来自不可信第三方数据 收集者的隐私攻击
定义 1. 给定 n 个用户,每个用户对应一条记录,给定一个隐私算法 M 及其定义域 Dom(M) 和值域Ran(M) ,若算法 M 在任意两条记录 t 和t’(t,t’∈Dom(M))上得到相同的输出结果t*(t*∈Ran(M))满足下列不等式,则 M 满足-本地化差分隐私.
![\[Pr[M(t)=t^<em>]<=e^ε </em> Pr[(M(t')=t^*]\]](https://shmilywz.top/wp-content/ql-cache/quicklatex.com-31dfc882b9b65855eb7779542bd21ecc_l3.png "Rendered by QuickLaTeX.com")
从定义一中可以看出,本地化差分隐私技术通过控制任意两条记录的输出结果的相似性,从而确保算法 M 满足-本地化差分隐私
差分隐私技术具有序列组合性和并行组合性两种特性
序列组合性强调隐私预算可以在方法的不同步骤进行分配,而并行组合性则是保证满足差分隐私的算法在其数据集的不相交子集上的隐私性
本地化差分隐私:每个用户按照隐私算法对数据进行扰动,然后把数据上传给数据收集者,数据收集者接收数据分析者的查询请求,并进行响应.
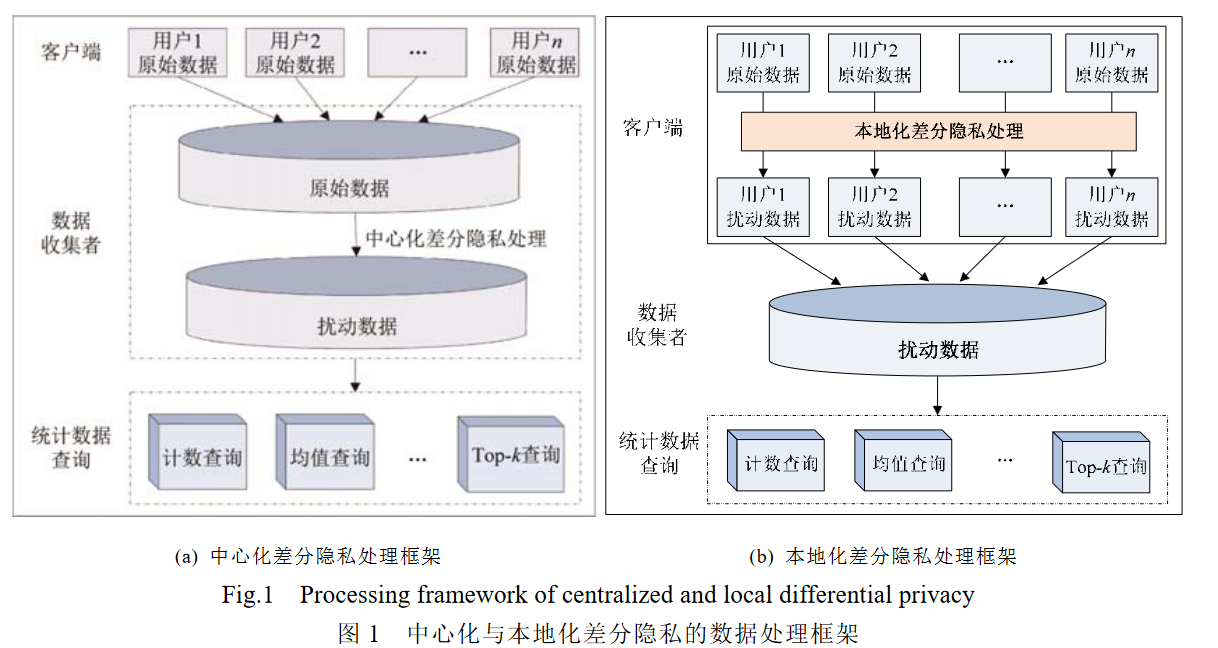
在中心化差分隐私保护技术中,为保证所设计的算法满足-差分隐私,需要噪声机制的介入,拉普拉斯机制和指数机制是其最常用的两种噪声机制,其中拉普拉斯机制面向连续型数据的查询,而指数机制面向离散型数据的查询
中心化差分隐私技术通过定义全局敏感性为查询结果添加响应噪声,再以
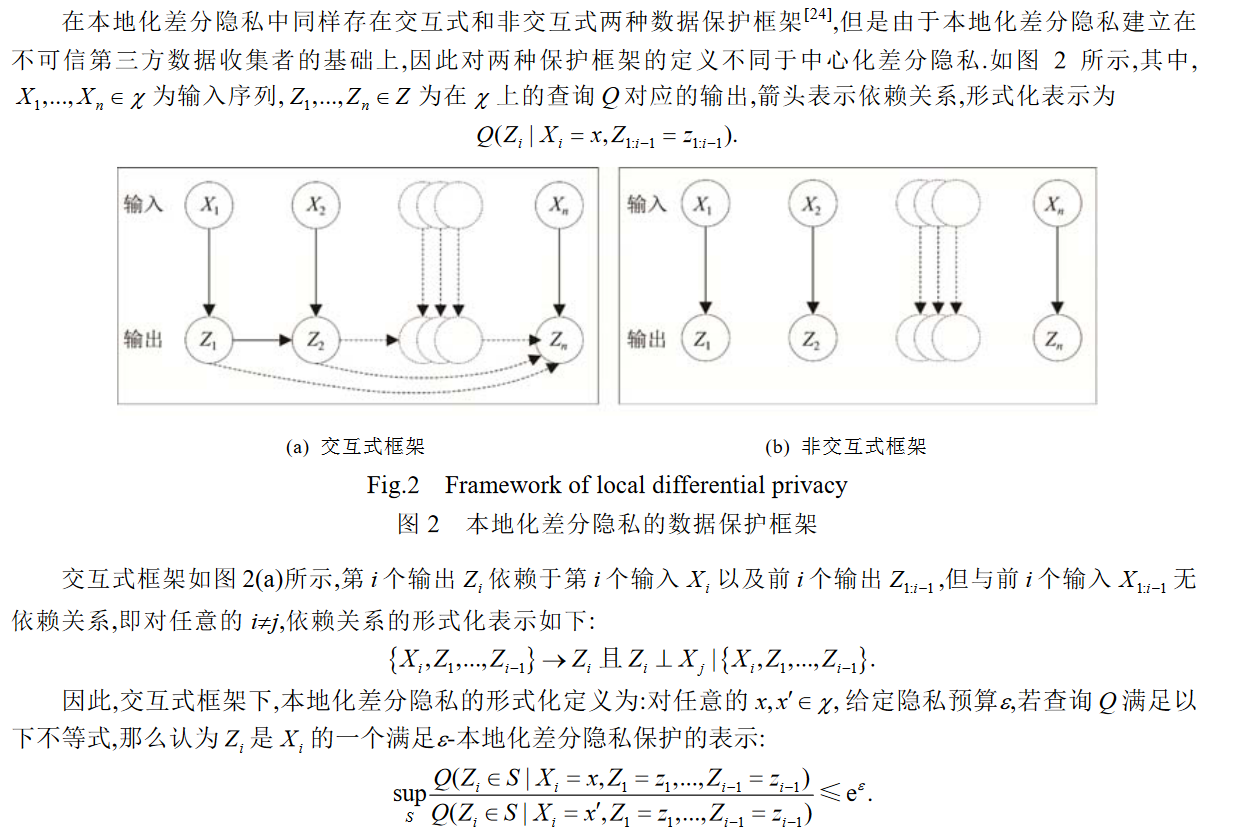

交互式和非交互式数据保护框架的最大区别在于输出结果之间的关联性.
(1) 交互式框架适用于最终输出结果与前 i 个输出有依赖关系的情形,如通过家族病史数据进行疾病诊断。家族病史数据记录了家族成员对于某些疾病的患病情况,由于遗传等因素,其中通常存在前后的关联 关系.在对此类数据进行本地化差分隐私保护时,由于某个个体的数据会对其他个体的输出产生影响,因此需要考虑用交互式框架对其进行保护
(2) 非交互式框架适用于前后的输入输出之间无依赖关系的情形,如商场的购物数据分析.一般而言,不同用户的购物清单数据之间不存在相互的关联关系,因此,在对该类数据进行本地化差分隐私保护时,直接应用非交互式框架即可.

本地化差分隐私下的研究工作大都基于随机响应技术展开,包括针对离散型数


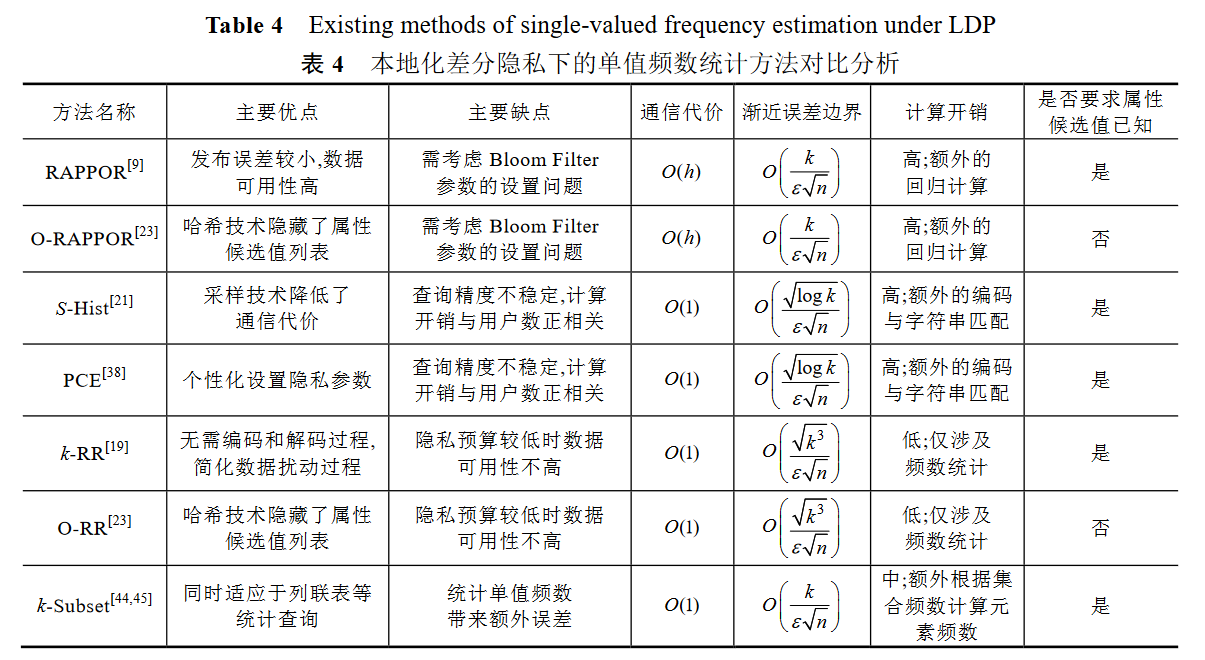
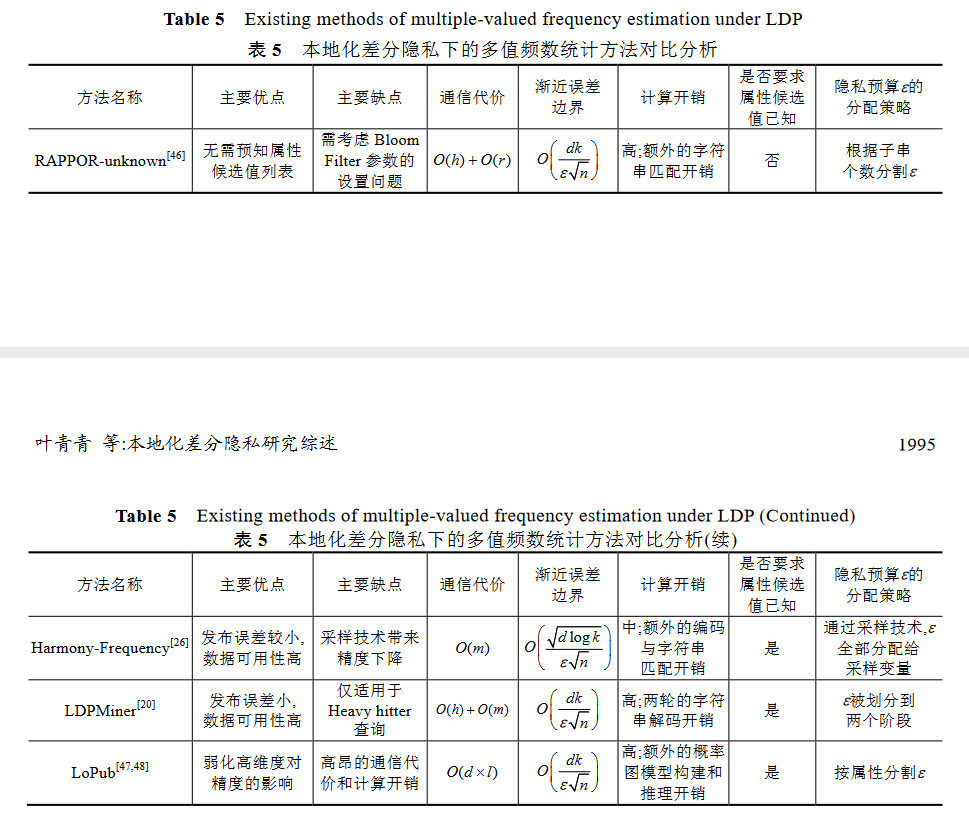


从定义来看,本地化差分隐私技术对数据的保护程度主要依赖于隐私预算的设定
对隐私保护而言,隐私保护程度与数据可用性呈负相关,隐私保护程度高则数据可用性低,隐私保护程度低 则数据可用性高.本地化差分隐私中,隐私保护的程度同样由参数决定,它通过控制随机响应技术输出真实值 的概率值来控制数据的偏离程度,进而保护隐私.
对于本地化差分隐私技术的保护机制而言,不同的隐私预算直接决定了随机响应技术中用于响应真实结果的概率 p,越大,则 p 越大, 即用户以更高的概率响应真实结果
在本地化差分隐私技术中,无论是频数统计还是均值统计,当给定相同隐私预算时,用于统计的数据量大小决定了数据可用性高低,数据量大则统计结果的可用性高,数据量小则统计结果的可用性低.