
Differential Privacy in DeepLearning
本文所了解到的知识来自于论文《Analysis of Application Examples of Differential Privacy in DeepLearning》,根据自己理解所做的笔记,如有错误欢迎指出
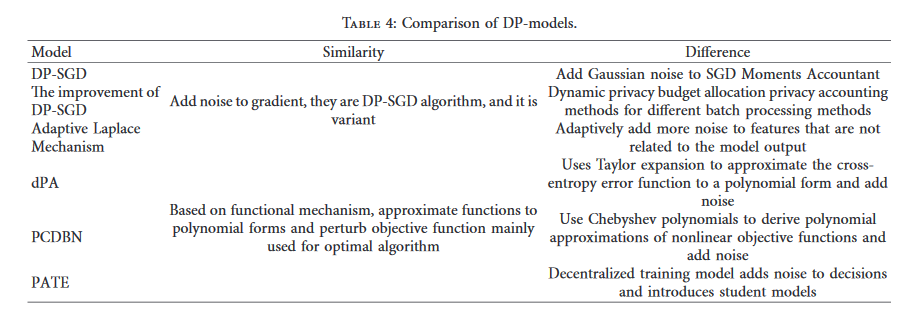
在本文中,我们分析六个在深度学习方面的差分隐私保护模型:
- DP-SGD,
- the improved DP-SGD
- Adaptive Laplace Mechanism(自适应拉普拉斯机制)
- dPA
- PCDBN
- PATE
这些模型可以被分为三种类别:
第一类:在梯度下降算法中加入噪声实现差分隐私,通过对梯度进行裁剪,然后将精心设计的噪声添加到梯度裁剪过程中实现隐私保护,DP-SGD,the improved DP-SGD,Adaptive Laplace Mechanism属于这一类
第二类:基于目标函数扰动机制,在目标函数中加入扰动以实现差分隐私,dPA和PCDBN属于这一类
第三类:这一类是一个新的框架,通过知识聚合和传播保护隐私,也可以说是基于标签扰动的差分隐私保护方法,PATE属于这一类
第一类:基于梯度扰动隐私保护方法
DP-SGD全称为
DP-SGD算法的一个重要问题是在训练阶段跟踪隐私预算,提出了隐私计算方法Moments Accountant,相比于差分隐私的序列组合定理,其提供了更严格的累积隐私计算界限。
但是DP-SGD算法勋在两个主要的问题,一是在实现算法过程中,为了更高的效率,随机扰动通常用于批处理数据,然而这样会导致更高的隐私损失,使成员低估账户的隐私计算;二是DP-SGD算法需要多次迭代以计算隐私缺失。
为了解决这些问题,LeiYu等人提出了一种利用集中训练神经网络的差分隐私方法(CDP),CDP相较于传统的DP做了更多的计算,也提供了更强大的隐私保护,论文首先提出了一种动态隐私分配技术,然后发展为基于zCDP的针对不同数据批处理的隐私计算方法。
动态隐私预算分配:对于一个给定的隐私预算,最终模型的准确性取决于在训练中的隐私预算分配,隐私预算分配技术旨在优化训练过程中的隐私预算分配,使得差分隐私模型具有更高的精度。在动态隐私预算分配过程中,使用衰减函数逐渐减小每次迭代训练的差分隐私噪声尺度

自适应拉普拉斯机制:其主要思想是添加更多与模型输出结果不相关联的噪声特性,根据每个特性的贡献进行模型输出,拉普拉斯噪声注入与特性自适应。这种方法所产生的噪声和隐私预算注入不会积累在每一个训练步骤中。
第二类:基于目标函数扰动隐私保护方法
Deep Autoencoder(dA)是一个基本的深度学习模型,广泛应用与自然语言处理等领域。Autoencoder是一种无监督的学习算法,主要用于数据降维或特征提取,而deep Private Autoencoder(dPA)是在传统的dA上基于目标函数扰动实现差分隐私的算法,使用泰勒展开式近似熵误差函数多项式,然后注入噪声,以实现差分隐私。
pCDBN(Private deep convolutional belief network)私有深度卷积置信网络实际上是一个差分隐私版本的卷积神经置信网络,将切比雪夫不等式用于pCDBN近似非线性目标函数,将噪声注入这些多项式,使得每个隐藏层的训练阶段满足严格差分隐私,最后,隐藏层变成了满足隐私保护的隐藏层后,堆积在每一个隐藏层,和误差函数的多项式与softmax结合起来生成一个私有卷积神经置信网络。
基于目标函数扰动函数机制,通过向潜在空间注入Laplace噪声来扰动目标函数的系数,以确保训练数据的差分隐私,并且可以生成高质量的和逼真的数据样本,也不会泄露训练数据集中的敏感信息。
第三类:基于标签扰动隐私保护方法
Papernot等人利用差分隐私噪声的标签扰
此外,目前的研究主要集中在以统计方式发布隐私保护的数据,而未考虑上下文的动态性和相关性。为此,Ho等人在GAN中引入差分隐私标识符(Differential privacy identifier)作为第三方,生成器同时与判别器和标识符博弈,该标识符基于差分隐私和用户级隐私(User-level privacy)建立隐私约束,根据差分隐私预算的序列组合为连续数据发布提供隐私保障。并使用轨迹数据对
基于数据扰动的差分隐私GAN方法
论文《Analysis of Application Examples of Differential Privacy in Deep Learning》只提到了以上三类隐私保护方法,笔者在翻阅其他综述文件时发现了第四种方法----基于数据扰动的差分隐私GAN方法
当使用GAN生成数据时,数据扰动方法通过添加差分隐私噪声到训练数据实现GAN隐私保护。Li等提出图数据隐私保护方法,使用GAN对图数据执行匿名化操作,使得在不指定特定特征的情况下充分了解图的特征成为可能,并通过在图生成过程中向概率邻接矩阵添加差分隐私噪声来保护匿名图的隐私。Neunhoeffer等提出差分隐私Post-GAN增强,结合GAN训练期间获得的生成器序列产生的样本,以创建高质量的数据集,并使用差分隐私乘法权重方法对生成的样本重新加权。Indhumathi和Devi提出医疗保健Cramr GAN,该算法只在已识别的准标识符中添加差分隐私噪声,将最终结果与敏感属性相结合,其中匿名医疗数据被用作训练Cramr GAN的真实数据,Cramr距离用于提高模型的效率,而由医疗保健机构生成的数据可以实现隐私保护,并抵抗各种攻击。Imtiaz等提出结合差分隐私机制的GAN,通过直接向聚合数据记录添加噪声来生成逼真的隐私医疗数据集,可以生成高质量的差分隐私数据集,并保留原始数据集的统计特征。
综上,针对不同类型的数据,基于各种扰动策略的差分隐私 GAN 方法的总体思想是一致的。对于差分隐私 GAN 方法,目前主要使用隐私预算、距离或误差度量和成员推理攻击的准确率等评价指标对隐私保护进行分析,对数据效用分析主要使用机器学习任务的分类准确率,以及距离或误差、关联矩阵、Kernel 密度估计、生成分数、ROC-AUC、PRCAUC( Area under the precision recall curve) 、IS、 FID、JS 散度、直方图分布和图效用度量等作为评价指标。