
隐私保护计算 - 基础知识
本文转载自简书:隐私保护计算 - 基础知识原文
如有侵权请联系删除
一、基本概念
1. 隐私保护计算的定义
隐私保护计算(Privacy-Preserving Computing)是指在保护隐私信息的前提下,实现数据价值的分析和挖掘,即实现数据在加密的、非透明的状态下的计算,以保护计算各参与方的隐私信息安全。
隐私保护计算不是某项单点技术,而是一套技术体系,涉及密码学、分布式计算、人工智能、数据科学等众多领域。
隐私保护计算实现的是数据背后的价值和知识的流动和共享,真正实现“数据可用不可见”。
2. 隐私保护计算的基本架构
隐私保护计算架构体系中,分为三个逻辑角色:数据方、计算方和结果方。数据方是提供数据的组织或个人,计算方是提供算力的组织或个人,结果方是接收结果的组织或个人。
隐私保护计算实际部署中,实体至少要有两个,每个实体可以参与数据方、计算方或结果方中的一个或多个。
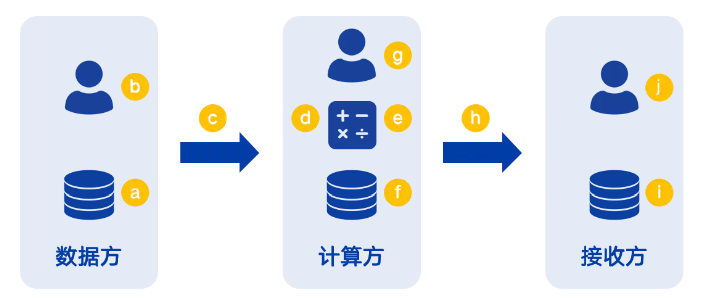
隐私保护计算的基本架构
3. 隐私保护计算的目标
- 隐私保护计算体系各环节的风险为:
1)数据方数据静态存储风险
2)数据方数据使用泄密风险
3)数据从数据方传输到计算方的传输风险
4)数据在计算方计算前的泄密风险
5)数据在计算方计算后的泄密风险
6)计算方数据静态存储风险
7)计算方数据使用泄密风险
8)数据从计算方传输到接收方的传输风险
9)接收方数据静态存储风险
10)接收方数据使用泄密风险 - 对于隐私数据的全生命周期防护过程,数据静态存储和数据传输的安全防护技术已经比较成熟,比如访问控制、存储加密、传输加密、内容审计等。而隐私计算保护,则专注于数据计算过程和计算结果的隐私保护,补齐隐私数据保护技术栈的短板。
4. 隐私保护计算的价值
- 打破数据孤岛。原始数据不出库,知识和价值出库,构建“数据可用不可见”的新模式,促进数据高效流转和共享交换。
- 安全合规避险。欧
ghgfhjfwenzhanglaixzizhenggegedboke@@@@ 盟PRACTICE项目依据GDPR论证了爱沙尼亚安全多方计算(1000万条纳税记录和60万学历信息的关联统计分析)的合规性,为欧洲高效数据流通树立典范。 - 弥合信任鸿沟。隐私保护计算技术栈依靠坚实的理论基础和安全行证明,从技术角度真正实现数据所有者的权利和数据使用者的义务之间的平衡,构建了信任基础。
二、关键技术
1. 联邦学习(Federated Learning,FL)
- 联邦学习最初由Google提出,用于解决由一个中央服务器协调众多分散的智能终端实现语言预测模型的更新。其工作原理是:
1)分布式的智能终端从中央服务器下载即有的预测模型,通过本地数据对模型进行训练,并将训练后的模型更新结果上传到中央服务器;
2)中央服务器对来自不同智能终端的模型更新进行融合,优化预测模型;
3)分布式的智能终端从中央服务器下载优化
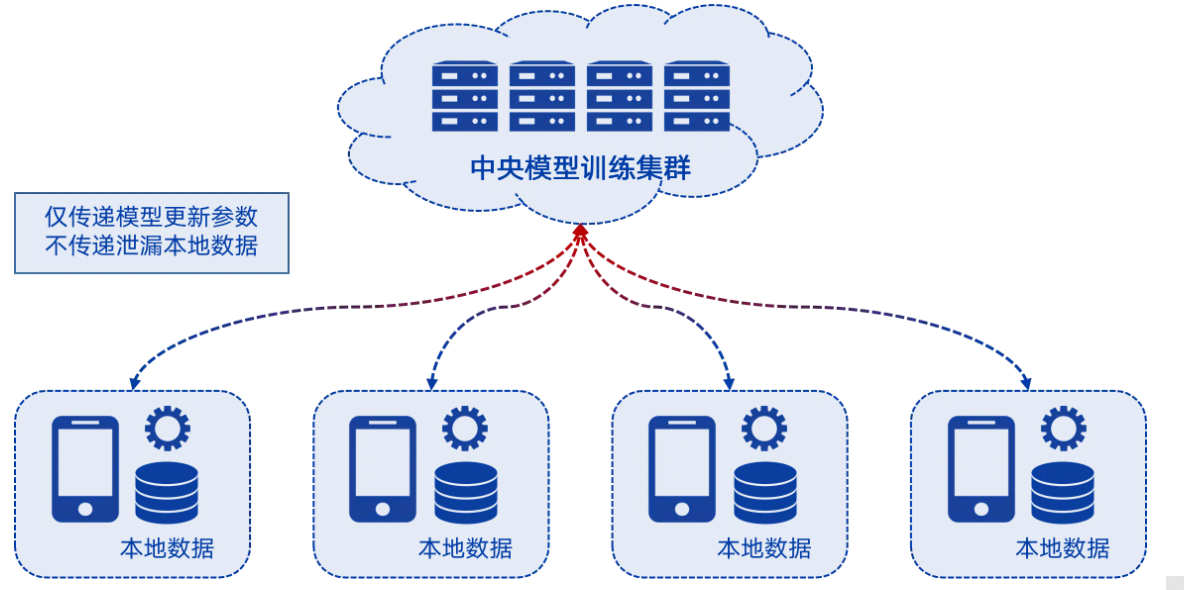
联邦学习
- 联邦学习的理念是保证数据不出安全控制范围的前提下,多方共同协作构建机器学习的模型,是一种训练数据分布式部署,实现参与方隐私数据保护的特殊的分布式计算方式。理论上可以取得和中心化机器学习模型训练近似的性能。
- 跟据训练数据的特征空间和样本空间的分布差异,FL分为三类:
1)横向联邦学习:各参与方特征重合度较高,样本重合度较低,通过扩充样本数目,提升模型训练效果的联邦学习模式。
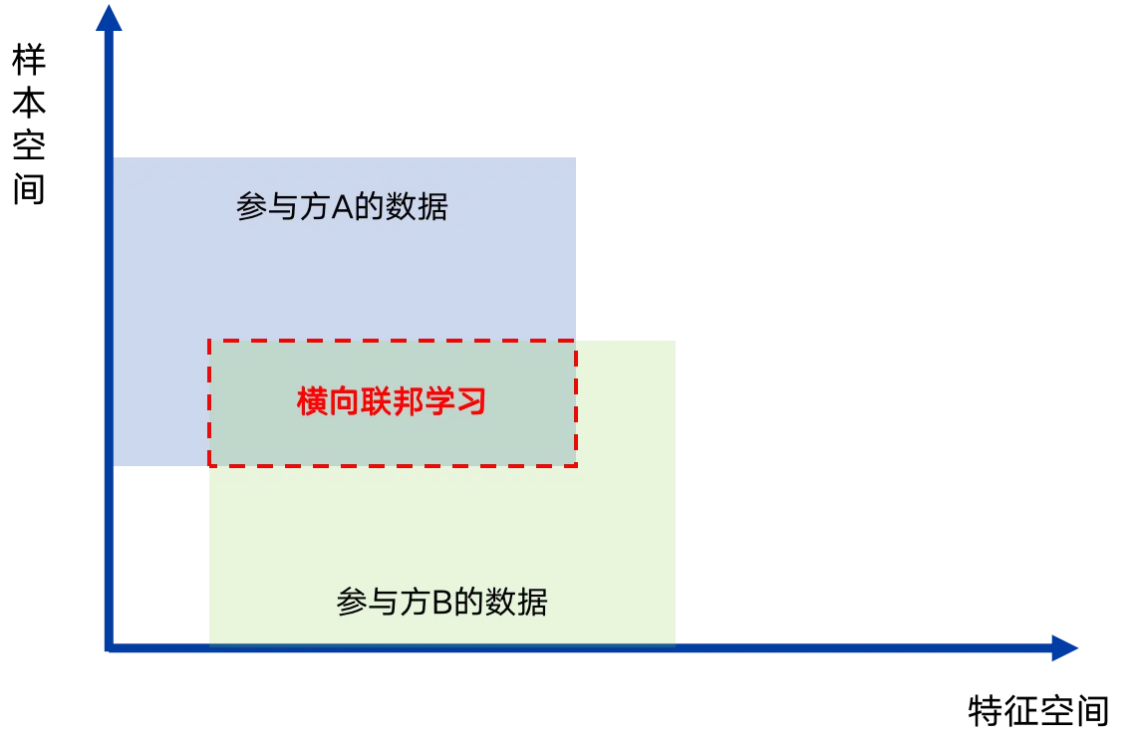
横向联邦学习
2)纵向联邦学习:各参与方特征重合度较低,样本重合度较高,通过丰富样本特征维度,提升模型训练效果的联邦学习模式。
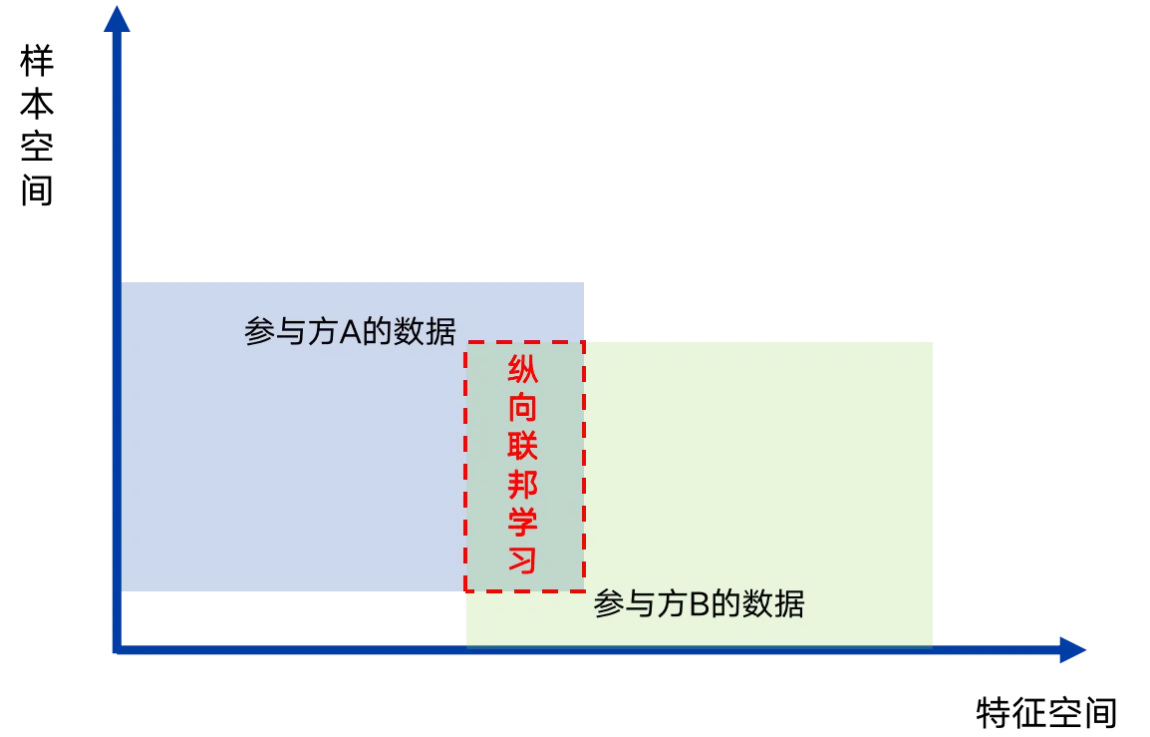
纵向联邦学习
3)联邦迁移学习:各参与方特征和样本的重合度均较低的联邦学习模式。
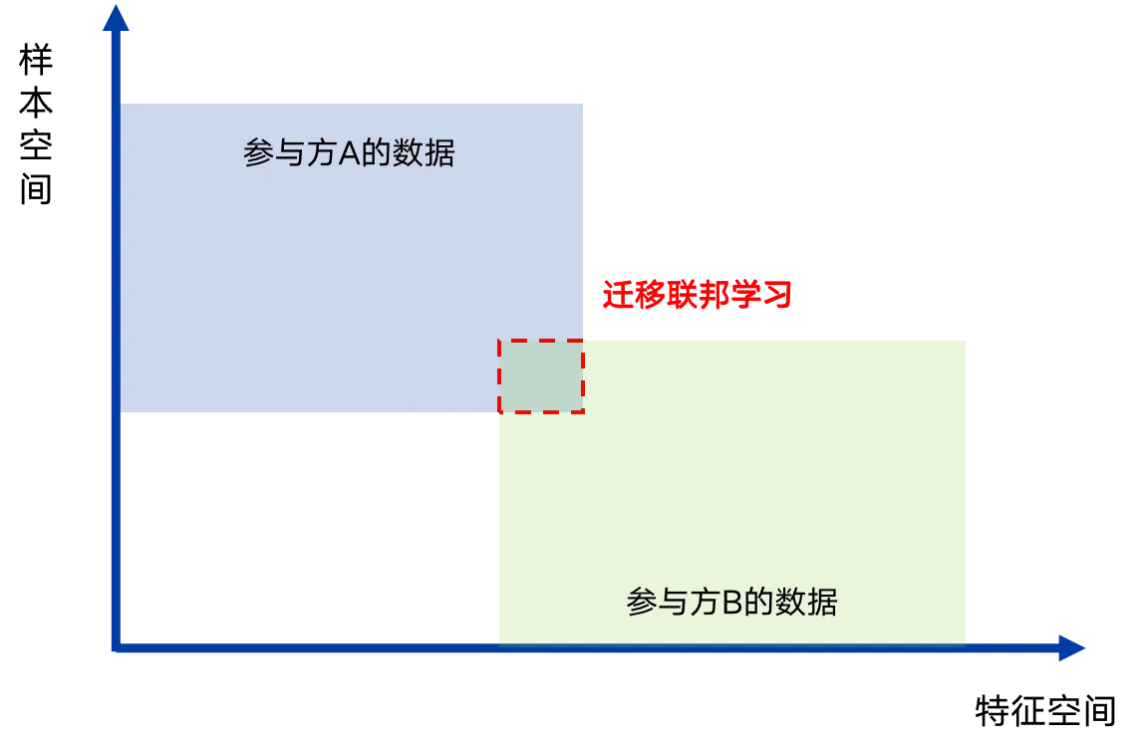
迁移联邦学习
- 联邦学习的典型架构:典型的联邦学习中,主要包含“协调方”、“数据方”和“结果方”三种角色。“数据方”是提供联邦建模训练所需的私有数据的参与方;“协调方”是协调各参与方进行协作训练的参与方;“结果方”是使用最终联邦训练模型的参与方,同一个参与方可以同时承担三种角色。联邦学习常见的算法有线性回归、逻辑回归、神经网络等。
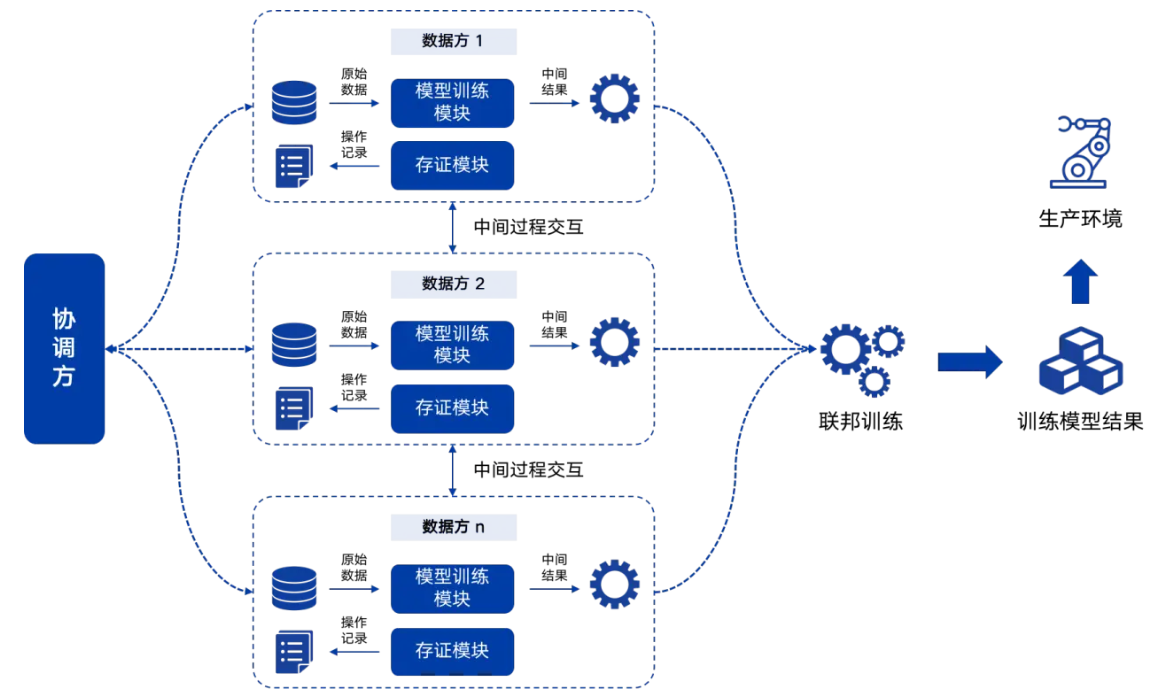
联邦学习部署架构
- 联邦学习的安全性评估:
1)理想情况下,联邦学习在模型训练和推理的阶段,各参与方只能获得其计算的必要过程数据和结果数据,也就是基于交互的有限数据无法推导出原始隐私数据。但现实为了兼顾实用性和公平性,往往要做一定的妥协。
2)联邦学习存在一定的安全问题:a)梯度带来的隐私泄露问题。虽然原始数据不出库,但梯度几乎包含原始数据信息,存在反向推导的问题。虽然原理上可以通过差分隐私添加噪声实现隐私保护,但这样会影响机器学习模型的收敛速度,对模型京精度产生损失;b)基于半同态加密(SHE)的单向隐私保护问题。部分纵向联邦学习技术采用SHE对中间过程结果进行加密,只能实现对私钥持有方的单向隐私保护。c)隐私求交的隐私泄漏问题。基于PSI(Private Set Intersection)协议,能够对非交集内的样本进行保护,但交集内的样本仍是明文,存在泄漏的风险。 - 联邦学习的典型场景:金融联合风控、联合营销、联合画像等
2. 安全多方计算(Secure Multi-Party Computation,SMPC)
- 安全对方计算最初由图灵奖获得者姚期智院士提出,用于解决“百万富翁问题”的一个算法设想。
- 安全多方计算解决的是一组相互不信任的参与方各自拥有秘密数据,协同计算一个既定函数的问题。参与方除了获得计算结果,无法获得之外的任何信息。在整个计算过程中,参与方拥有对自身数据的绝对控制权。
- 安全多方计算逻辑架构:同一个分布式网络中,有n个参与方P1,P2,P3,…,Pn,各自拥有自己的秘密数据xi(i=1,2,3,…,n),它们共同执行既定的函数y=f(x1,x2,x3…,xi),y为Pi的执行结果。Pi除了y得不到任何其他信息。
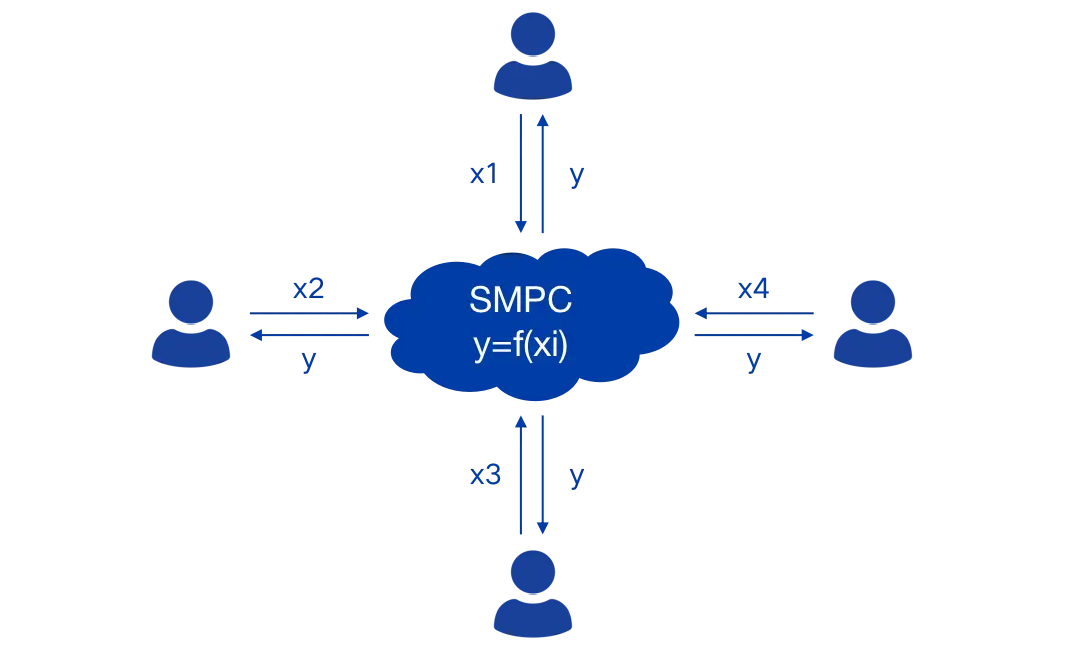
安全多方计算
- 安全多方计算的部署架构:在一次安全多方计算任务中,1)数据方将原始数据通过SS、GC或OT等方式,安全的发送给计算方;2)计算方按照SMPC协议进行协同计算,并将结果通过安全信道发送给结果方。一个参与者,可以同时承担多种角色。
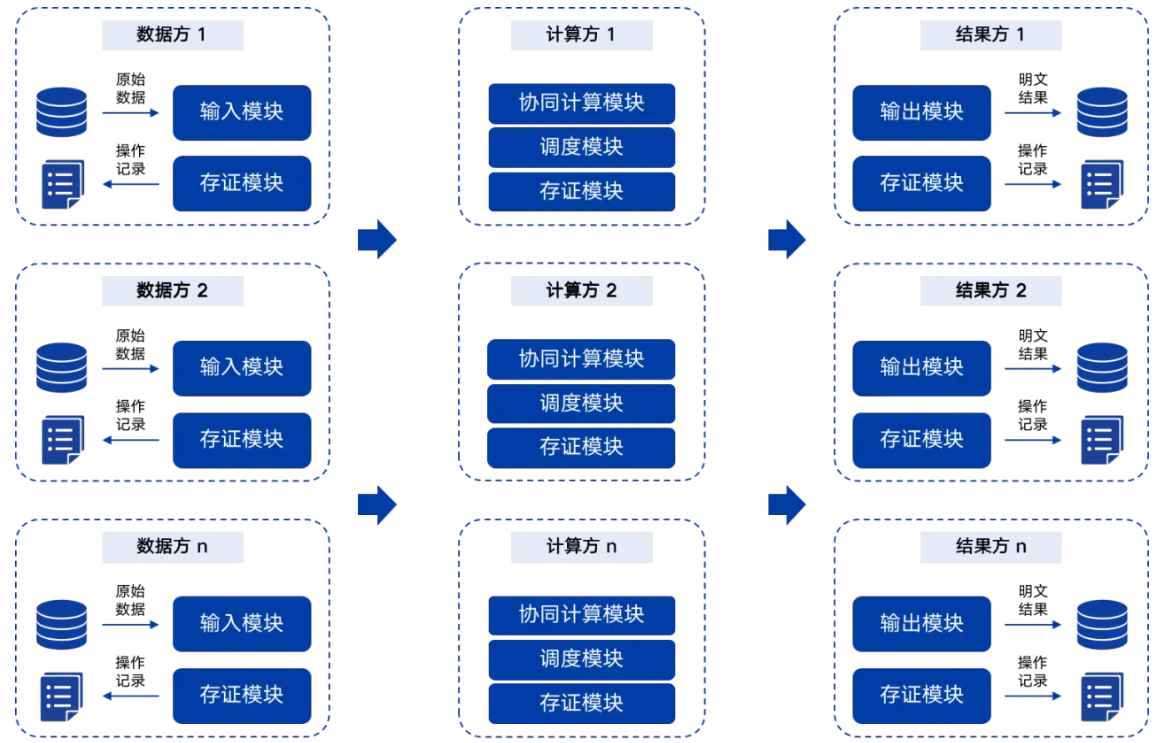
安全多方计算部署架构
- 安全多方计算拥有坚实的数学理论基础,也实现了过程和结果的严格定义:
1)输入隐私性:各参与方除了自身输入的秘密数据和既定函数结果输出以外,得不到任何其他数据。
2)正确性:各参与方遵守协议完成计算,都应该收到相同的、正确的输出结果。
3)公平性:恶意参与方能够获得计算结果的前提是,其他遵守协议的合法参与方已经获得了计算结果。
4)结果传递保证:遵守协议的各参与方,都能够保证收到正确的输出结果。
- 安全多方计算安全性的程度可以通过多种维度进行评估,最主要的是“行为模型”和“安全门限”:
1
2)安全门限:假设SMPC参与总方数为n,根据参与方是否可能合谋,分为“诚实大多数模型”和“不诚实大多数模型”。前者指可能合谋的参与方小于n/2;后者指可能合谋的参与方大于等于n/2。能够支持“不诚实大多数模型”的SMPC实现方案具备更强的安全性。
3)目前市场上主流的SMPC方案都是在“半诚实敌手模型”和“诚实大多数模型”下保持安全性。
- 安全多方计算的关键技术选型:
1)秘密分享(Secret Sharing):将秘密信息分割成若干“秘密份额”,分发给多个参与方保管,达到风险分散和入侵容忍的目的。SS方案由“秘密分割算法”和“秘密重组算法”组成,包括“秘密份额分发者”、“秘密份额持有者”和“秘密份额重组者”三个角色。“秘密份额分发者”负责执行“秘密分割算法”,将分割的“秘密份额”分发给“秘密份额持有者”。“秘密份额重组者”从一组“秘密份额持有者”处收集“秘密份额”,执行“秘密重组算法”重组秘密信息。一个SS参与方可以身兼多种角色。SS方案有“消息机密性”和“消息可恢复性”两种属性。“消息机密性”指一组“秘密份额持有者”拥有的“秘密份额”不足以进行秘密重组,“秘密份额持有者”就无法重组秘密信息。“消息可恢复性”是指一组“秘密份额重组者”拥有足够的“秘密份额”进行重组,它们就可以合并各自的“秘密份额”重组秘密信息。
2)混淆电路(Garbeld Circuit):姚期智院士提出的针对“半诚实敌手模型”的两方安全计算协议,当然也可以支持三方及以上方数。GC的核心思想是将任何函数计算问题转换为由“与门”、“或门”、“非门”组成的布尔逻辑电路,再结合密码学技术构建加密版的布尔逻辑电路。GC分为电路构建和电路计算两个步骤。
3)不经意传输(Oblivious Transfer):OT协议下,最简单的是发送方
(Alice)拥有2个秘密消息x1和x2,接受方(Bob)只能选择其中一个秘密消息xb

不经意传输
- 安全多方计算的典型场景:
1)数据安全查询,数据查询方仅能得到结果,拿不到原始数据,数据拥有方也不知道查询方的具体查询请求;
2)联合统计分析,协同多方的数据进行联合的统计分析,增强改进已有的统计分析算法;
3. 同态加密
- 同态加密是一种特殊的加密算法,在密文基础上直接进行计算,与基于解密后的明文是一样的计算结果。

同态加密
- 目前同态加密主要基于非对称密码算法,公钥是公开的,所有知道公钥的参与方都可以进行加密和密文计算,但只有私钥持有者才能解密最终结果。
- 同态加密可以分为半同态加密和全同态加密:
1)半同态加密(Somewhat Homomorphic Encryption,SHE):支持有限密文计算深度,比如支持无限次密文加,但只能支持一次密文乘。由于这个限制,一般很难基于SHE实现完整的隐私保护方案
2)全同态加密(Fully Homomorphic Encryption,FHE):支持无限密文计算深度,比如支持无限次后密文加和密文乘。由于计算代价过高,目前还处在实验室阶段。
4. 机密计算(Confidential Computing,CC)
- 机密计算是基于硬件可信执行环境(Trust Execution Environment)实现数据和应用保护的技术,Gartner也将其称为Enclave(借助政治上的“飞地”概念)。其核心思想是以可信硬件为载体,提供硬件级强安全隔离和通用计算环境,在完善的密码服务加持下形成“密室”,数据仅在“密室”内才进行解密并计算,除此之外任何其他方法都无法接触到数据明文内容。
- 需要注意的是,加密技术只是机密计算技术选择之一,机密计算也在探索其他方案。
- TEE目前较为成熟的技术:
1)Intel SGX(Software Guard Extensions):本质上是CPU维度的TEE机制。将CPU划分出一些被保护的Enclave区域(对应应用程序的地址空间),称为Enclave容器。当应用程序和数据加载到Enclave容器中,Intel SGX能够保证只有Enclave容器内的代码才能访问Enclave容器内的数,操作系统级别的特权和非特权用户,都不能访问,这是CPU层面实现的机制。
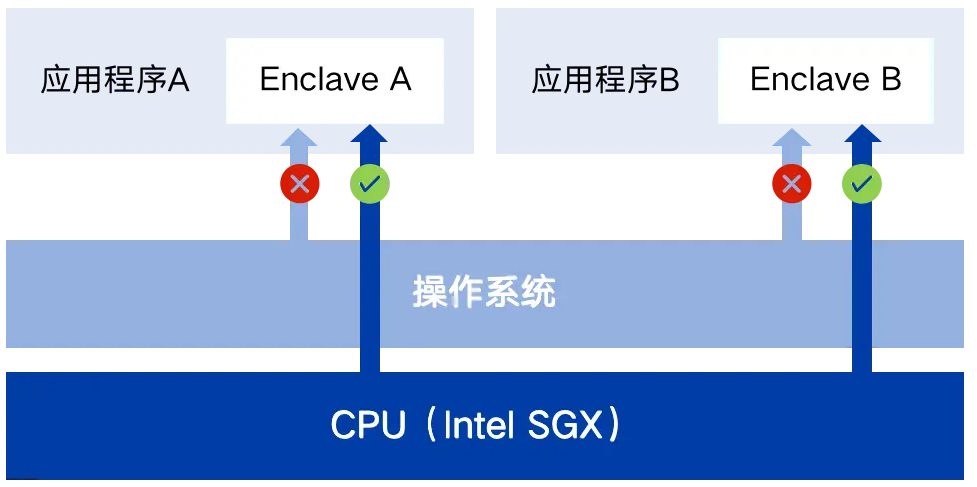
Intel SGX
2)ARM TrustZone:本质上操作系统维度的TEE机制。将硬件和软件资源划分为“安全环境(Secure World)”和“普通环境(Normal World)”。“安全环境”需要更高的执行权限,“普通环境”的应用程序无法直接对“安全环境”中的数据进行访问,必须经过操作系统严格的检验。也就是说,TrustZone的安全性由操作系统来负责。
-直接基于TEE进行应用开发是比较底层和复杂的,因此出现了一些应用开发框架,将底层复杂的机制和实现进行封装,对应用程序提供易用的接口。由于服务器领域主要的架构仍然是X86,因此基于Intel SGX的框架占据了主流:
1)百度Rust SGX SDK:基于Rust语言,封装Intel SGX。底层是Intel SGX,中间层是Rust和C/C++的FFI(Foreign Function Interfaces),上层是Rust SGX SDK。
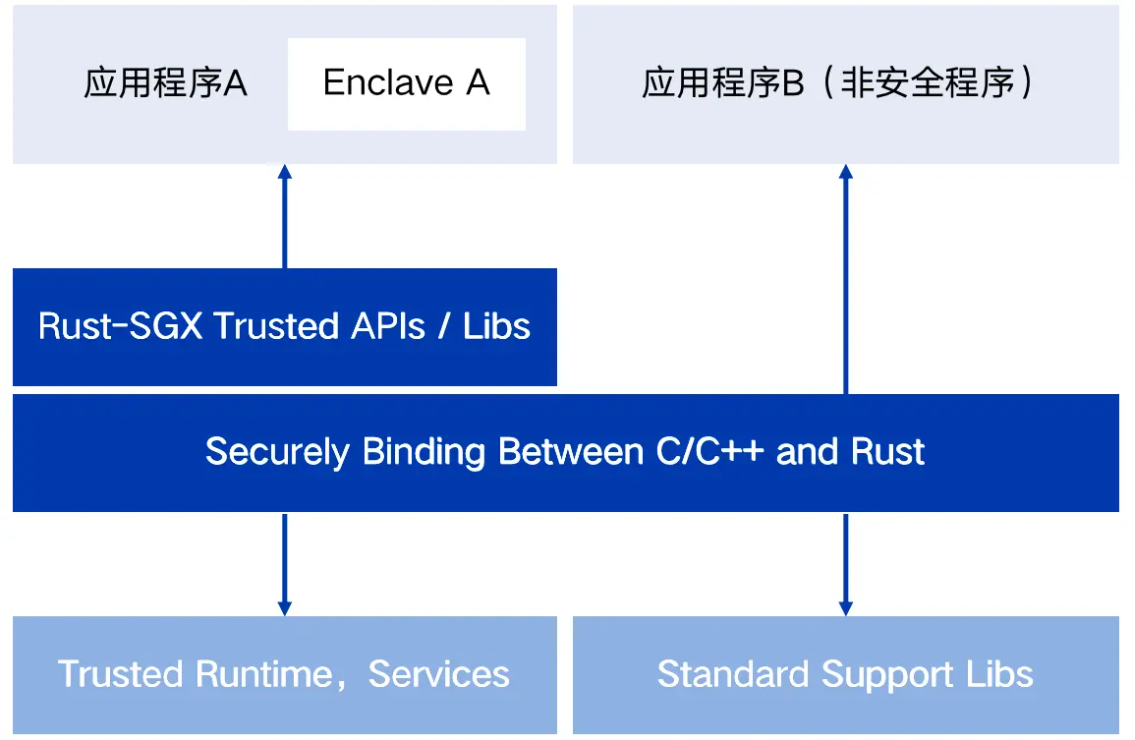
百度 Rust SGX SDK
2)谷歌Asylo:目标是通过一套框架,支持各种TEE。主要使用的类是TrustedApplication、EnclaveClient和EnclaveManager。处于普通应用程序空间中的代码若想进入Enclave空间,相当于进行系统调用,Enclave的入口会对其进行严格检查。
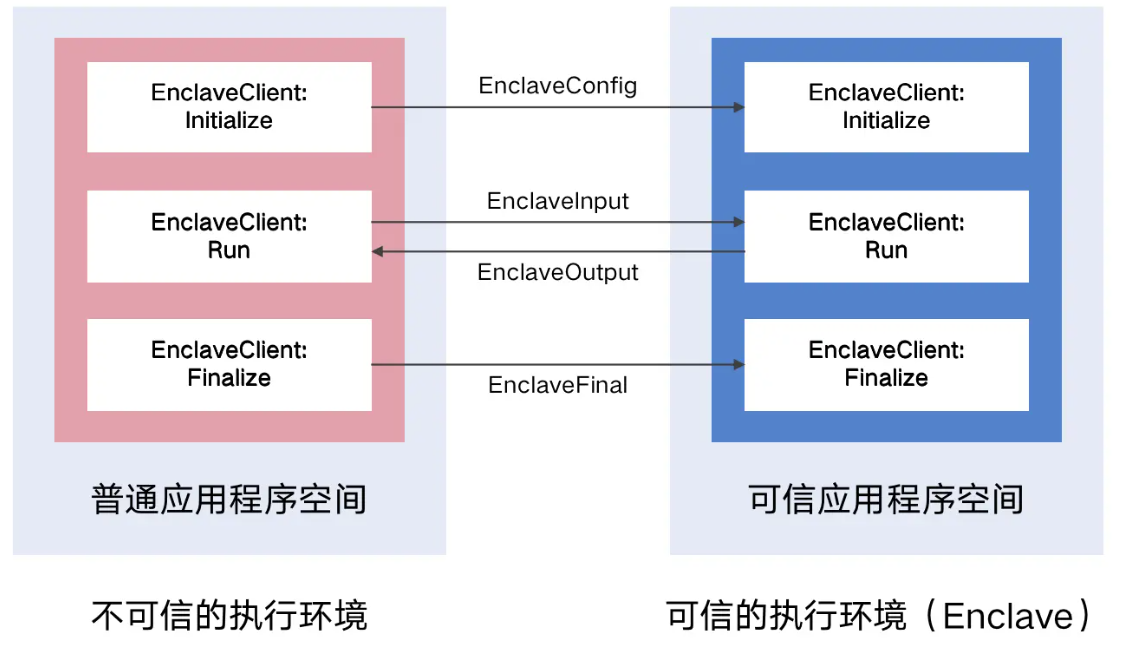
谷歌Asylo
- LibOS技术:LibOS相当于在操作系统内核之上提供了一份精简版的内核和软件运行库。LibOS可以作为TEE,主机OS可以相互分离,为应用程序提供单独的安全环境。应用程序之间只能通过LibOS进行通信。这种方式的优点是可以较为快捷的将原有程序迁移到TEE环境中,无需重新开发;缺点是将整个LibOS都作为T
ghgfhjfwenzhanglaixzizhenggegedboke@@@@ EE。这和虚拟机架构中Guest和HostOS有些类似。
5. 差分隐私(Differential Privacy,DP)
- 本质是对计算结果的保护,而不是计算过程;联邦学习、安全多方计算以及机密计算则是对计算过程以及计算过程中间结果进行保护。
- 差分隐私具备严谨的数学理论,其核心优点在于:
1)和背景知识严格无关的隐私保护模型,理论了上可以抵御任何攻击(这有点像密码学领域中的一次性密码本)
2)建立在严格的数学理论基础上,对隐私保护提供了量化的评估方法和严谨的数学证明。这点也非常类似密码学中的经典算法,比如DES、AES、椭圆曲线等。 - 差分隐私当前最主要的实现方式是在结果集中添加噪声,解决单个查询的隐私保护问题。添加噪声的核心问题是噪声对模型分析的可用性影响,如何能够在安全性与可用性上找到平衡,是差分隐私的重点研究方向。
6. 技术对比
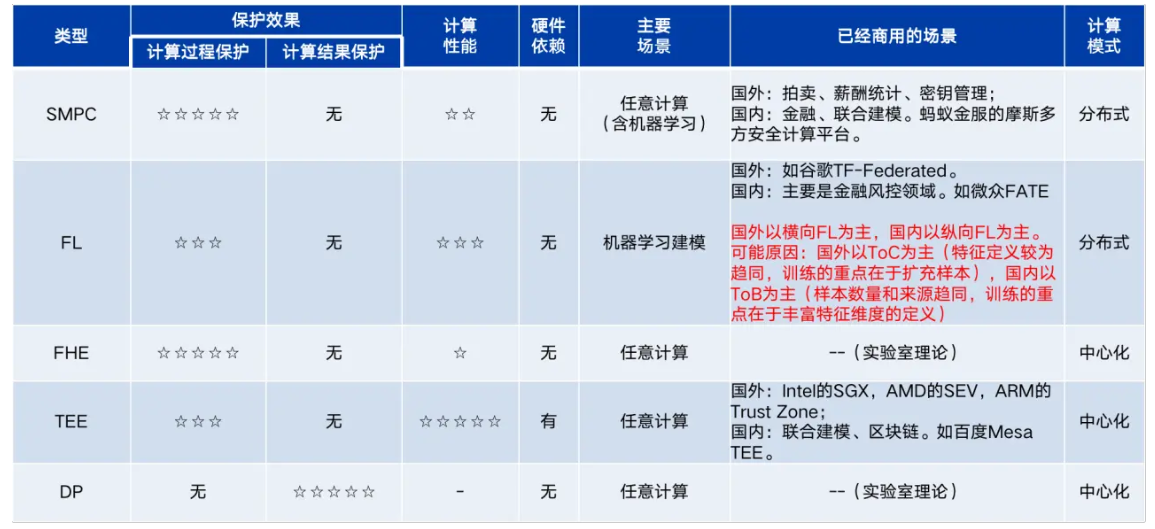
技术对比
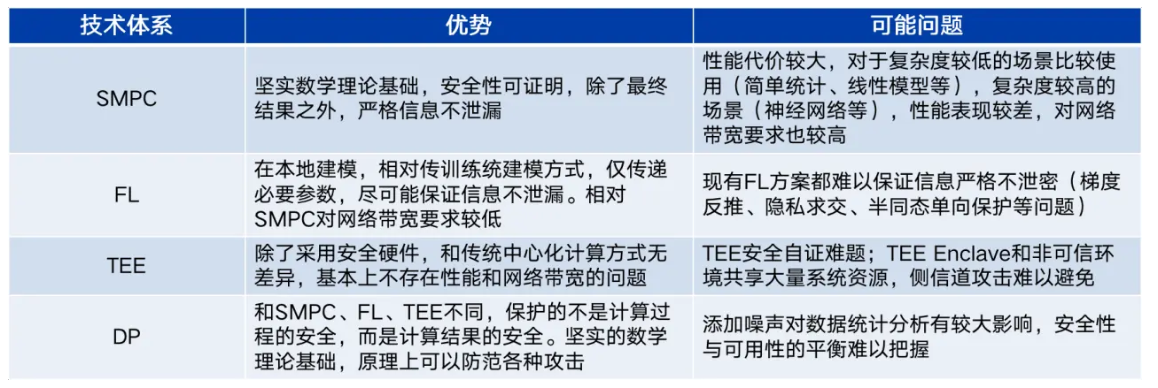
优劣势对比
三、应用场景
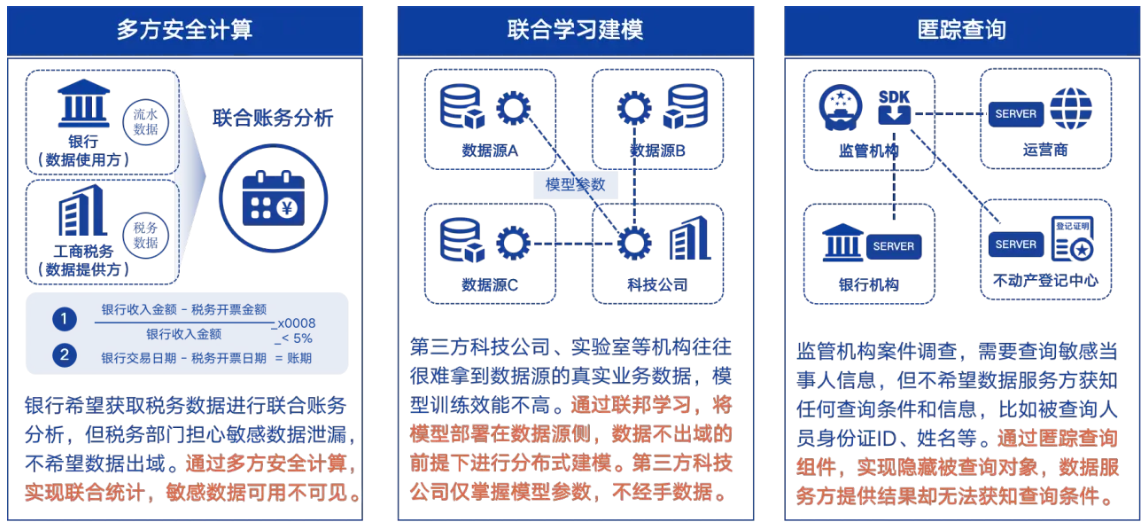
应用场景
四、开源项目
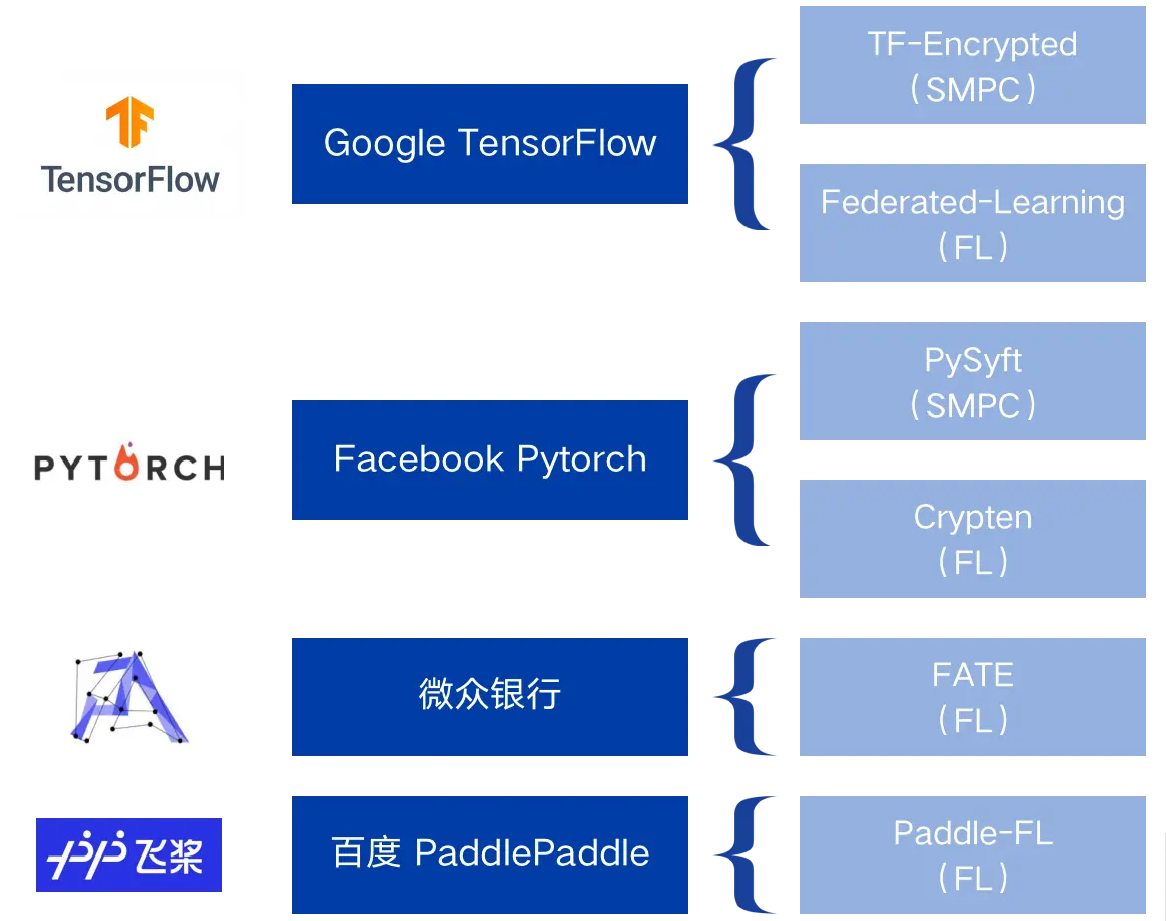
开源项目关系
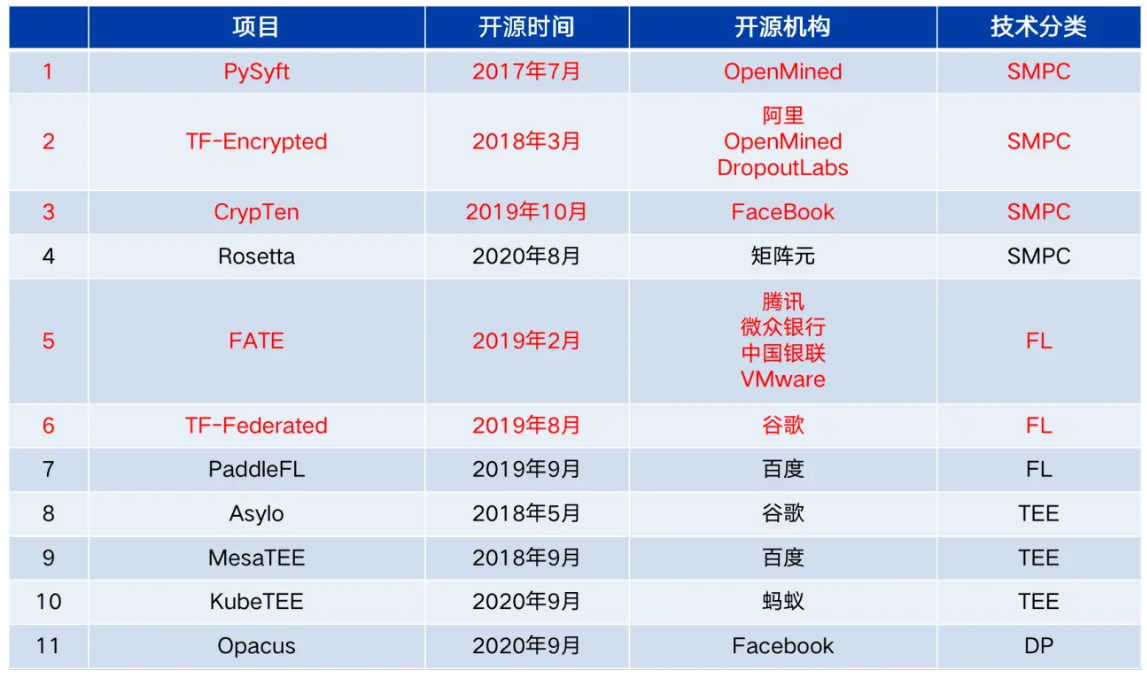
开源项目列表