
差分隐私算法在数据安全中的应用
此前在DataFunTalk上看到一篇中国人民大学刘勇老师分享的一篇《差分隐私算法在数据安全中的应用》,个人认为很适合初学者理解,现做笔记整理。
原文链接:https://zhuanlan.zhihu.com/p/569946271
本人只做自己学习笔记,具体转载事项请联系原作者。
隐私保护的挑战
本文将更关注“模型的隐私保护”,而不完全是“数据的隐私保护”。
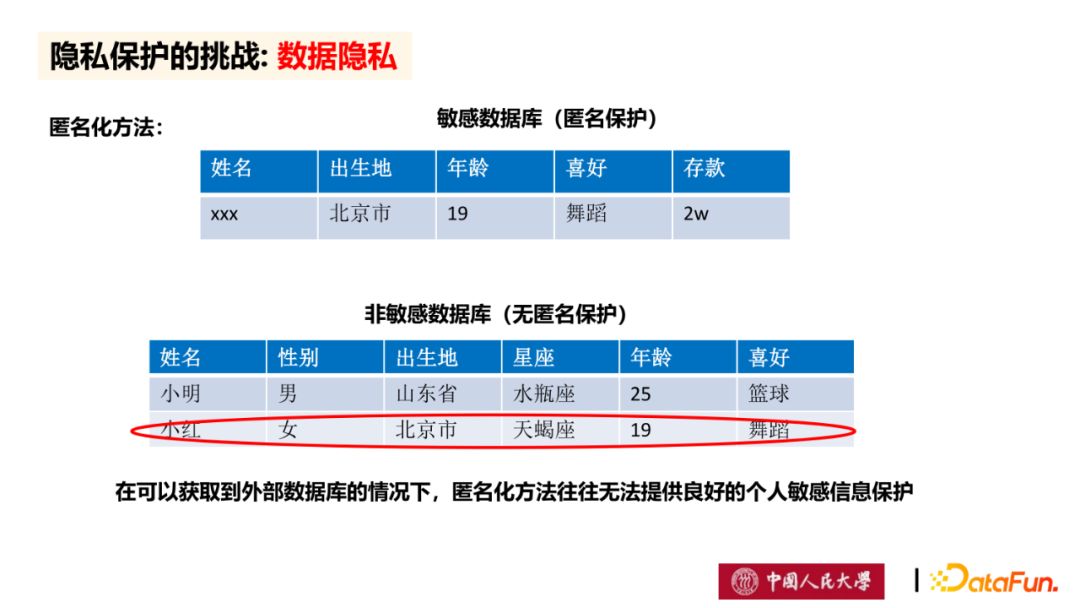
匿名化方法是较为常用的隐私保护的方法。在对外发布的数据库中,机构主体通常会将姓名等敏感信息做匿名化处理。但是,在大数据时代,由于可以获取到外部数据库,通过比对和关联分析,可以推理出敏感信息,而造成隐私信息泄露。因此匿名化方法往往无法提供良好的个人敏感信息保护。
另一个数据匿名出错的案例研究是网飞奖比赛。 Netflix是一家非常数据驱动和统计思维的公司:他们的许多热门电视节目都是基于用户数据构思的,他们传说中的推荐算法经过调整,以优化用户参与度。 2006年至2009年间,他们举办了一场竞赛,挑战研究人员改进他们的推荐引擎。 大奖是一个广为人知的100万美元,由一个名为Bellkor的务实混沌的团队根据矩阵分解技术获得。为了帮助团队设计他们的策略,Netflix提供了一个用户数据的培训数据集。 每个DataPoint由一个(匿名的)用户ID、电影ID、分级和日期组成。 网飞向用户保证,这些数据被适当地去匿名化,以保护个人隐私。 事实上,1988年的《视频隐私保护法》要求他们这样做。 一个人的媒体消费历史通常被认为是敏感或私人信息,因为一个人可能消费与某些少数群体有关的媒体(包括政治或性性质的媒体)。不幸的是,Narayanan和Shmatikov证明,这种匿名化的新形式不足以保护用户隐私[NS08]。 他们的方法如图所示 1.他们采用了Netflix提供的数据集,并将其与在线电影数据库IMDB的公开信息进行交叉引用,该数据库包含数亿条电影评论。 特别是,他们试图通过寻找在相似的时间对一部电影给出相似评分的用户来匹配两个数据集之间的用户。 虽然Netflix的数据被取消了身份,IMDb的数据没有,但一项评论与用户名或联机假名相关联。 事实证明,这种方法足以从几个弱匹配中重新识别许多用户,从而提供这些用户的电影观看历史信息,他们选择不公开这些信息。 这一发现导致了针对Netflix的集体诉讼,并取消了续集比赛。
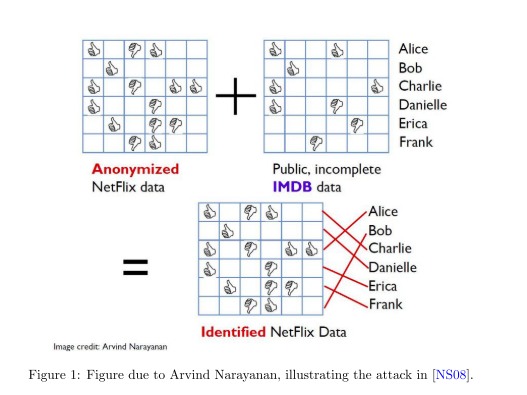
这个例子再次表明,去匿名化不足以保证隐私,尤其是在存在附带信息的情况下。
相反,在机器学习领域,如果不发布数据,而只发布训练模型,个人隐私仍然不能得到有效的保障,例如,模型的逆向攻击或者成员推理攻击,都可以通过对模型的解析推理窃取原始数据。因此,为了保护数据,我们需要寻找有数学保证的隐私保护方法。
而差分隐私从数学上给出了严格的证明,可以有效屏蔽包括成员推理攻击、属性推理攻击等攻击手段,因此,受到了Google、苹果、微软等科技公司的关注并被广泛应用。
差分隐私原理
这一部分可以查看我之前的概念介绍文章:差分隐私,大同小异,这里就不再赘述
差分隐私算法

arg,复数辐角,英文名称argument of a complex number, 指的是复数的辐角主值。
数学在argmax g(t)中,表达的是定义域的一个子集,该子集中任一元素都可使函数g(t)取最大值。
差分隐私有三种添加随机噪声的方式以保证模型的差分隐私性。(其实是有四种,具体可以查看我之前写的博客)
(1)输出扰动:
输出扰动方法的基本思想是:在通过
输出扰动方法的优点是:操作简单,原理清晰。
缺点是:对输出模型的扰动可能会影响模型的性能,甚至会导致输出模型无法应用到新数据集。
(2)目标函数扰动:
目标函数扰动方法的基本思想是:在机器学习模型所需要优化的目标函数中加入噪声,得到满足差分隐私定义的机器学习模型 。
目标函数扰动的缺点是:对目标函数的扰动可能会使模型不能收敛到最优,而影响模型的性能。
(3)梯度扰动(应用最广泛):
梯度扰动的基本思想是:对每一回合中目标函数的梯度加入噪声,得到满足差分隐私定义的机器学习模型。
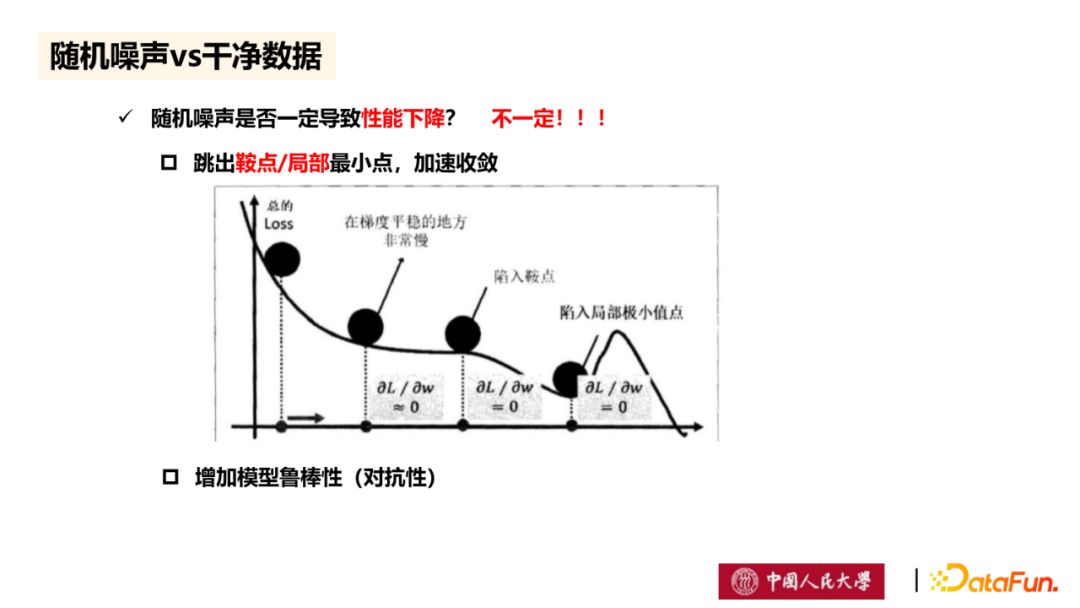
但在模型中加入随机噪声并不一定导致性能下降,如图所示,通过梯度扰动的方法,在目标函数的梯度加入噪声,将可能跳出鞍点/局部最小点,并加速收敛。此外,对于满足差分隐私定义的机器学习模型中,由于已经加入噪声,将减少由数据样本扰动所引起的模型性能下降,即增加模型鲁棒性。
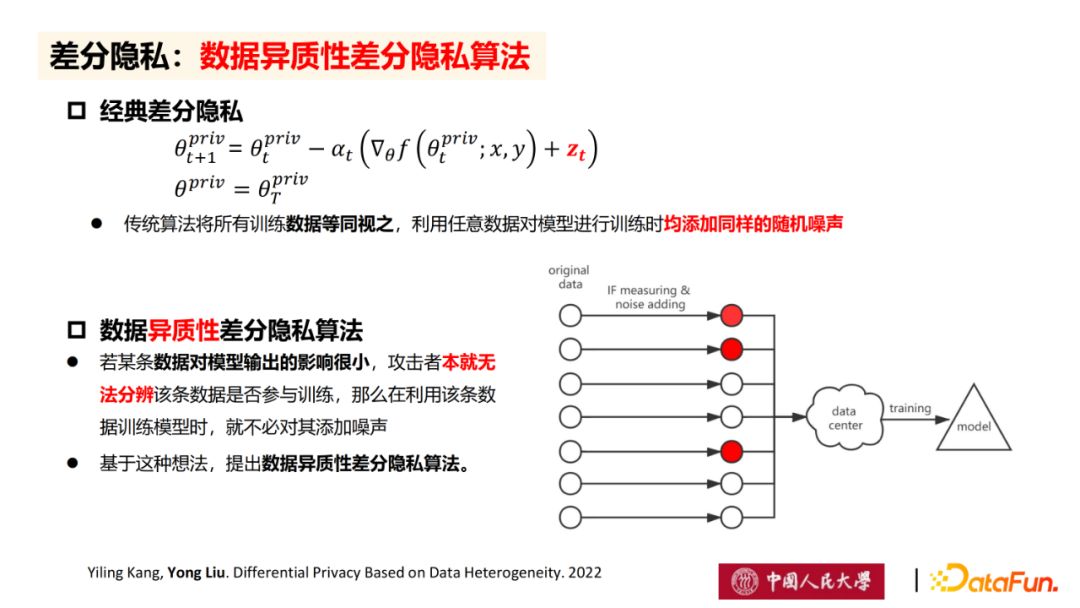
在传统的差分隐私算法中,将所有训练数据等同视之,利用任意数据对模型进行训练时均添加同样的随机噪声。但是在实际训练时,不同的数据点对模型的贡献是不同的,因此,对于一些贡献
在改进的数据异质性差分隐私算法中,若某条数据对模型输出的影响很小,攻击者本就无法分辨该条数据是否训练,那么在利用该条数据训练模型时,就不必对其添加噪声。(这点是中心)

相较与传统的差分隐私算法,改进的数据异质性差分隐私算法将在梯度下降前先对数据点对模型的性能进行判断。具体的,每一回合进行梯度更新时,将计算每一个数据点对于最终模型性能的影响分数,并设置阈值,如果影响分数小于阈值,说明影响很小,以至于攻击者无法从中得到有用的信息,那么则不添加噪声,以此减少模型训练中噪声添加的总量,进而提升模型精度。
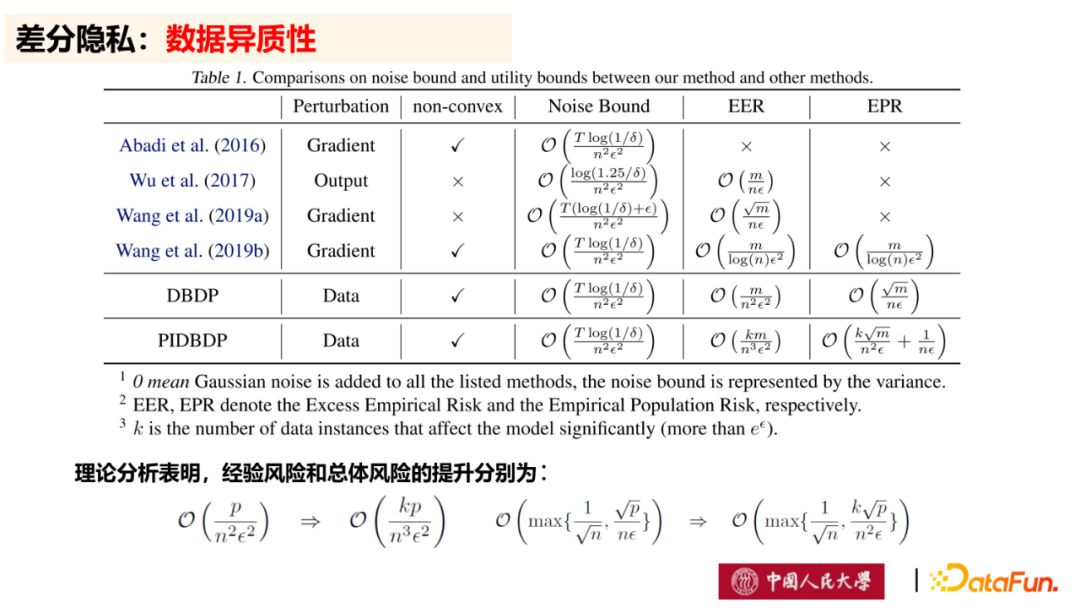
如图所示,是我们提出的数据异质性差分隐私算法与其他经典差分隐私算法的比较,可以发现,我们提出的数据异质性差分隐私算法在经验风险和总体风险上是有提升的。此外,由于实际问题大多是非凸问题,我们需要注意差分隐私算法在非凸问题上的应用,而数据异质性差分隐私算法是可以保证非凸问题的求
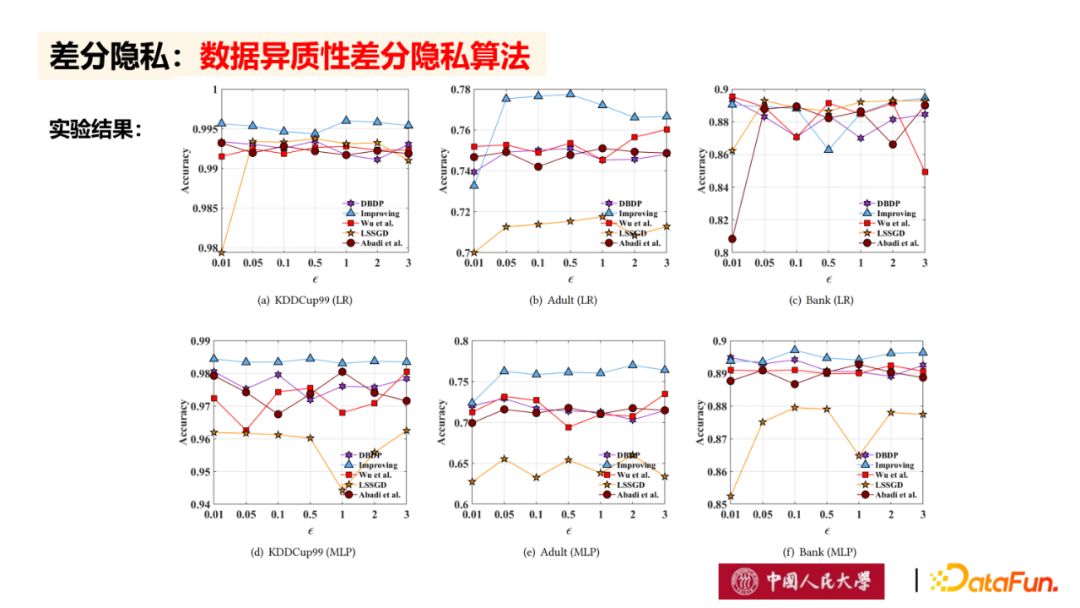
上图为数据异质性差分隐私算法与其他经典差分隐私算法的实验比较结果,从图可以看出,总体上数据异质性差分隐私算法在准确率上是最高的,并且在凸问题和非凸问题上都具有最高的模
--
作者在后面还有讲到差分隐私在联邦学习上的应